消息队列—区别/对比/选型
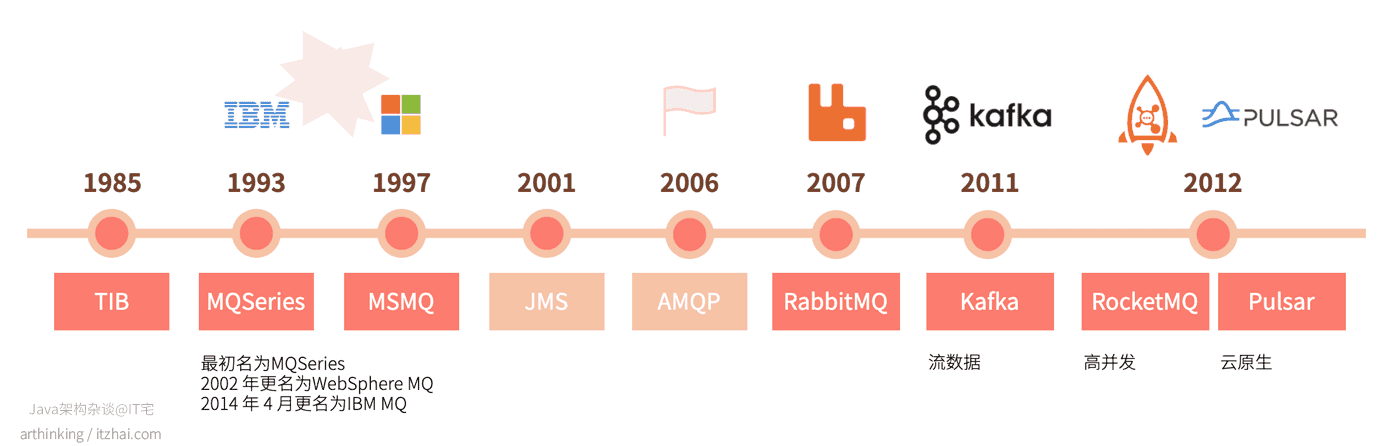
- 什么是消息队列
- 消息队列的应用场景
- 消息队列技术选型,Kafka还是RocketMQ,还是RabbitMQ
- 消息中间件如何做到高可用?
- 消息队列如何解决消息丢失问题
- 消息队列有可能发生重复消费吗?如何幂等处理?
- 如何处理消息队列的消息积压问题
- 消息队列如何保证消息的顺序性。
- 如何保证数据一致性,事务消息如何实现
- 如果让你写一个消息队列,该如何进行架构设计?
消息队列应用场景
异步处理
系统解耦
流量削峰
引入消息队列的劣势分析
引入一个技术,要对这个技术的弊端有充分的认识,才能做好预防。
一个使用了MQ的项目,如果连MQ的缺点都没有考虑过,就把MQ引进去了,那就会给自己的项目带来风险。
- 系统可用性降低
系统的可用性会受消息队列的可用性影响。 - 系统复杂度提高
引入消息队列后,要多考虑很多方面的问题。
消息丢失、消息重复消息、消息可靠传输、消息积压、数据一致性等等。
需要考虑的东西多了,系统复杂性随之增加。 - 一致性问题
消息中间件基本架构
架构组成
- Producer 生产者,消息的产生方,生产者会将消息发送到消息队列。
- queue 消息队列,接受并存储生产者的消息。
- Consumer 消费者,消费消息队列中的消息。
两种模式
点对点模式(一对一)
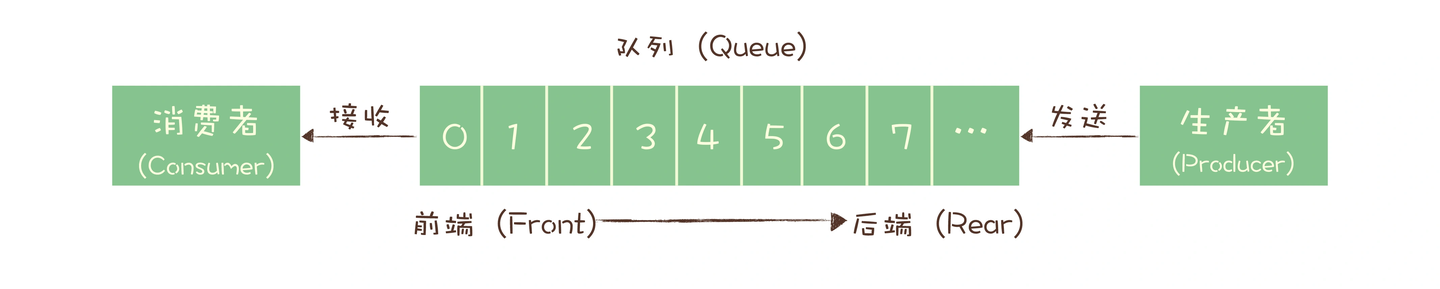
早期的消息队列,就是按照 “队列” 的数据结构来设计的,生产者发消息是入队操作,消费者收消息就是出队动作,服务单存放消息的容器就是 “队列”。
消费者之间是竞争关系,如果想要将一份消息分发给多个消费者,要求每个消费者都能收到全量的消息,单个队列就无法满足,一个比较笨的解决方法就是为每一个消费者创建一个消息队列,让生产者发送多份。
但是这样缺点比较明显:一是一份数据复制多份,浪费资源,二是生产者必须知道有多少个消费者,违背了 “解耦” 的设计初衷。
发布-订阅模式(一对多)
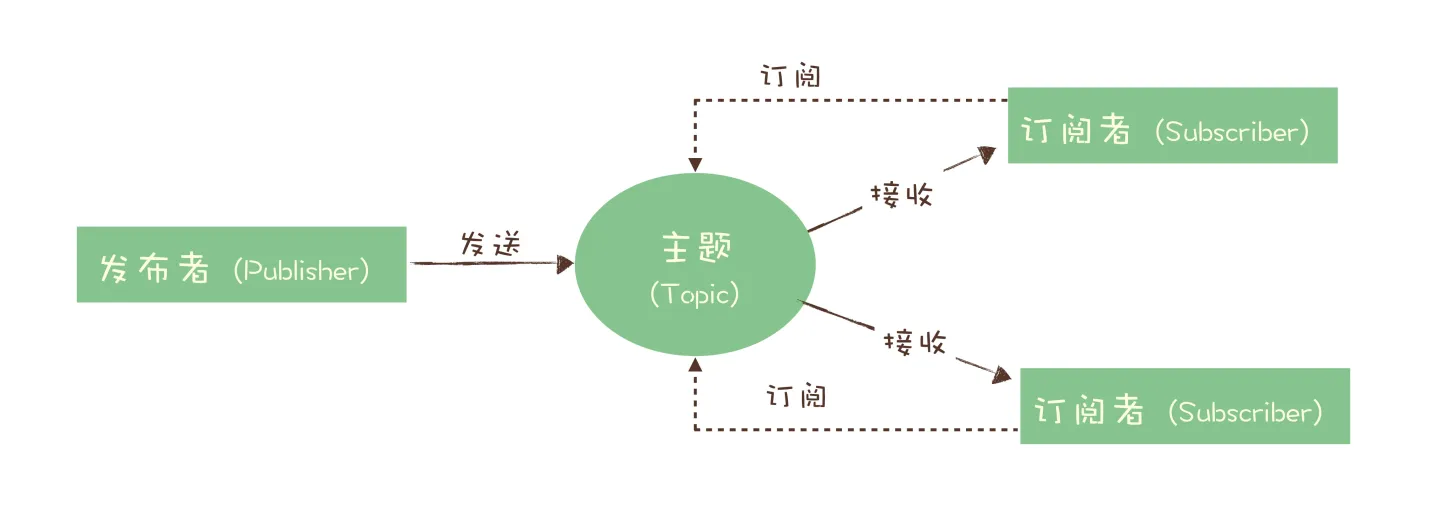
在发布-订阅模型中,消息的发送者称为发布者(Publisher),消息的接收方称为订阅者(Subscriber),服务端存放消息的容器称为主题(Topic)。
发布-订阅模型与队列模型之间最大的区别就是 一份消息数据能不能被消费多次的问题 。
消费者消费完消息后,消息不会被删除,消息会存储一段时间,这种模式下的消息会被所有订阅该主题的消费者消费。
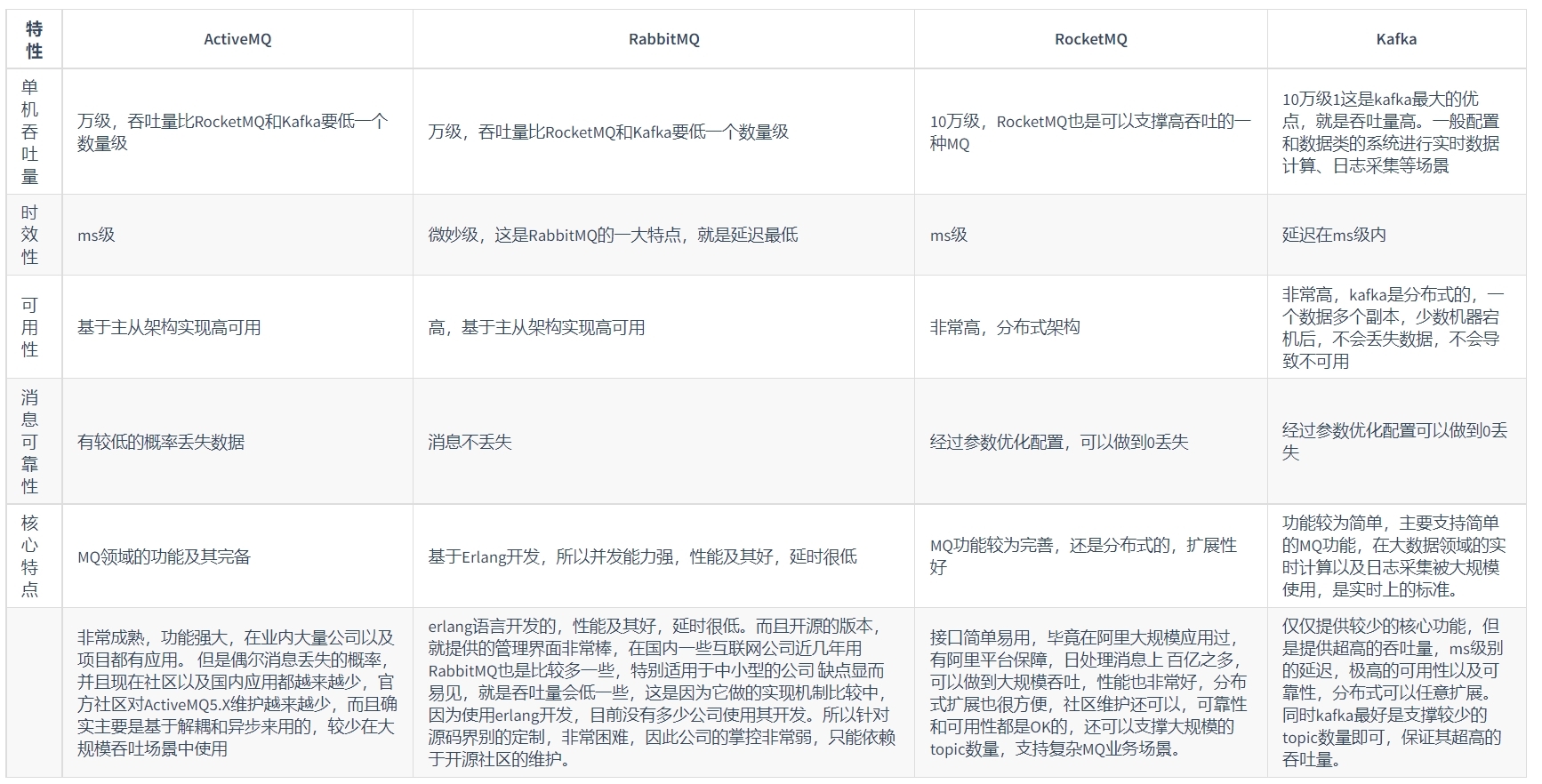
技术选型
- RabbitMQ
如果消息队列不是将要构建系统的重点,对消息队列功能和性能没有很高的要求,只需要一个快速上手易于维护的消息队列,建议使用 RabbitMQ。 - RocketMQ
如果系统使用消息队列主要场景是处理在线业务,比如在交易系统中用消息队列传递订单,需要低延迟和高稳定性,建议使用 RocketMQ。 - Kafka
- 优点:兼容性极好、设计上大量使用了批量和异步的思想,有超高的性能
- 缺点:由于 “先攒一波再一起处理” 的设计,时延较高,不太适合在线业务场景
- 如果需要处理海量的消息,像收集日志、监控信息或是埋点这类数据,或是你的应用场景大量使用了大数据、流计算相关的开源产品,那 Kafka 是最适合的消息队列。
Kafka
1. 高可用
Kafka基于Partition分区和Replica副本来保证高可用。
Kafka 集群由若干个 Broker 组成,Topic 由若干个 Partition 组成,每个 Partition 可存在不同的 Broker 上。可以这样说,一个 Topic 的数据,分散在多个机器上,即每个机器上都存放一部分数据。
- Kafka 0.8以前
Kafka 0.8 以前是没有高可用机制的。
假设一个 Topic,由 3 个 Partiton 组成。3 个 Partition 在不同机器上,如果其中某一台机器宕掉了,则 Topic 的部分数据就丢失了。 - Kafka 0.8以后
Kafka 0.8 以后,通过副本机制来实现高可用。
2. 消息丢失
经过参数优化配置,能够做到零丢失。
生产阶段:Producer丢失数据
如果 Producer 端设置了 acks=all,则不会丢失数据。Leader 在所有的 Follower 都同步到了消息之后,才认为本次写成功。如果没满足这个条件,生产者会进行无限次重试。
在生产阶段,需要捕获消息发送的错误,并重发消息。
存储阶段:Broker丢失数据
比较常见的一个场景:Kafka 某个 Broker 宕机,然后重新选举新的 Leader ,但此时其他的 Follower 部分数据尚未同步,结果此时 Leader 挂了(宕机的Broker就是该分区的leader),然后选举某个 Follower 成 Leader,丢失一部分数据。
一般设置如下 4 个参数:
- Topic 设置
replication.factor参数
参数值必须大于 1,要求每个 Partition 必须有至少 2 个副本。 - Kafka 服务端设置
min.insync.replicas参数
参数值必须大于 1,要求每个 Partition 必须有至少 2 个副本。 - Producer 设置
acks=all
要求每条数据,必须是写入所有副本,才认为写成功。 - Producer 端设置
retries=MAX
MAX 即是一个超级大的数字,表示无限次重试。retries=MAX要求一旦写入数据失败,就无限重试。
消费阶段:Consumer丢失数据
默认情况下,Kafka 会自动提交 Offset,Kafka 认为 Consumer 已经处理消息了,但是 Consumer 可能在处理消息的过程中挂掉了。重启系统后,Consumer 会根据提交的 Offset 进行消费,也就丢失了一部分数据。
解决:关闭自动提交 Offset,在处理完之后自己手动提交 Offset,就可以保证数据不会丢失。但可能会存在消息重复消费问题。
3. 重复消费
消费者相关参数
enable.auto.commit:表示消费者会周期性自动提交消费的offset。默认值true。auto.commit.interval.ms:在enable.auto.commit为true的情况下,自动提交的间隔。默认值5秒。max.poll.records:单次消费者拉取的最大数据条数,默认值500。max.poll.interval.ms:表示若在阈值时间之内消费者没有消费完上一次poll的消息,consumer client会主动向 coordinator 发起LeaveGroup请求,触发Rebalance;然后consumer重新发送JoinGroup请求。session.timeout.ms:group Coordinator 检测consumer发生崩溃所需的时间。在这个时间内如果Coordinator未收到Consumer的任何消息,那Coordinator就认为Consumer挂了。默认值10秒。heartbeat.interval.ms:标识Consumer给Coordinator发一个心跳包的时间间隔。heartbeat.interval.ms越小,发的心跳包越多。默认值3秒。- Group Coordinator
对于每一个Consumer Group,Kafka集群为其从Broker集群中选择一个Broker作为其Coordinator。Coordinator主要做两件事:- 维持Group成员的组成。这包括加入新的成员,检测成员的存活性,清除不再存活的成员。
- 协调Group成员的行为。
重复消费的原因
- 原因1:消费者宕机、重启或者被强行kill进程,导致消费者消费的offset没有提交。
- 原因2:设置
enable.auto.commit为true,如果在关闭消费者进程之前,取消了消费者的订阅,则有可能部分offset没提交,下次重启会重复消费。 - 原因3:消费后的数据,当offset还没有提交时,Partition就断开连接。比如,通常会遇到消费的数据,处理很耗时,导致超过了Kafka的
session timeout.ms时间,那么就会触发reblance重平衡,此时可能存在消费者offset没提交,会导致重平衡后重复消费。
解决方法
保证消费消息的幂等性。
什么是幂等性,它本来是一个数学上的概念,如果函数f(x) 满足 **f(f(x)) = f(x)**,则函数满足幂等性。
这个概念被拓展到计算机领域,被用来描述一个操作、方法或者服务,一个幂等操作的特点是 其任意多次执行所产生的影响均与一次执行的影响相同。
一个幂等的方法,使用同样的参数,对它进行多次调用和一次调用,对系统产生的影响是一样的。
如何实现接口的幂等性?
4. 消息积压
使用消息队列的时候,大部分的性能问题都出现在消费端,如果消费的速度跟不上发送端生产消息的速度,就会造成消息积压。
如果这种性能倒挂是暂时的,问题不大,如果消费速度一直比生产速度慢,时间长了,整个系统就会出现问题,要么消息队列的存储被填满无法提供服务,要么消息丢失,这对于整个系统来说都是严重故障。
一定要保证消费端的消费性能要高于生产端的发送性能,这样的系统才能健康的持续运行。
消费端的性能优化除了优化消费业务逻辑以外,也可以通过水平扩容,增加消费端的并发数来提升总体的消费性能。
特别需要注意的是,在扩容 Consumer 的实例数量的同时,必须同步扩容主题中的分区(队列)数量,确保 Consumer 的实例数和分区数量是相等的。