QA
为什么会有ConcurrentHashMap
为什么HashMap线程不安全
为什么HashTable效率低下
ConcurrentHashMap在JDK1.7和JDK1.8中实现有什么差别? JDK1.8解決了JDK1.7中什么问题
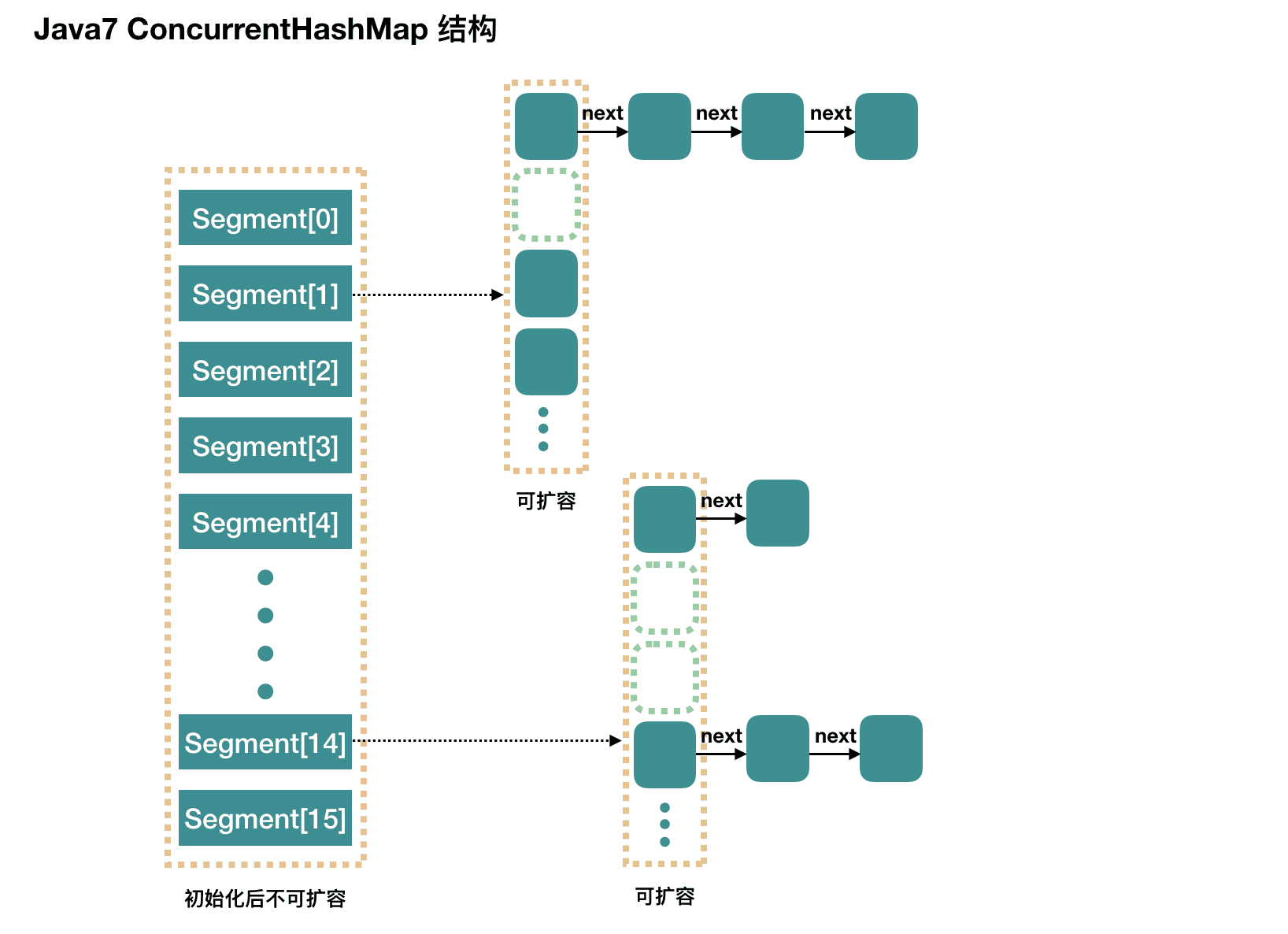
ConcurrentHashMap JDK1.7实现的原理是什么? 分段锁机制
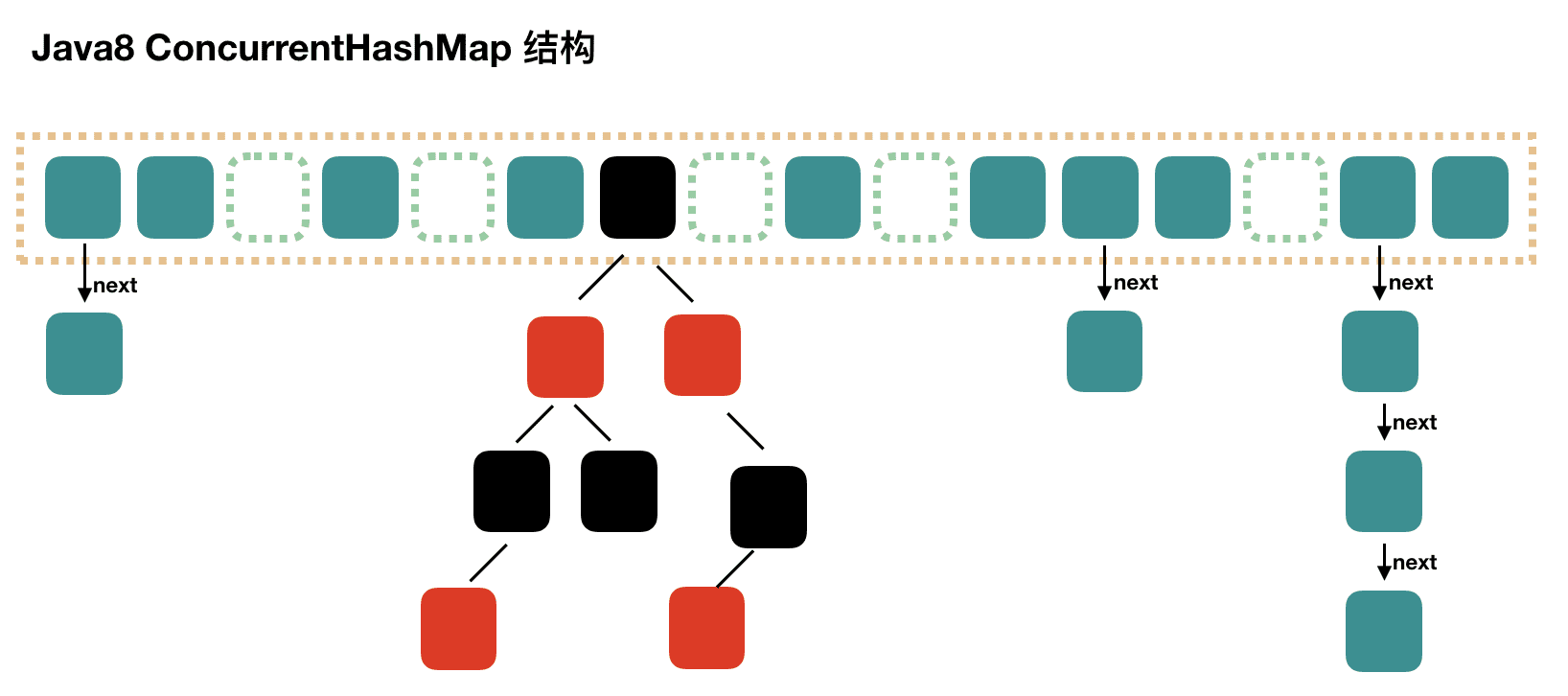
ConcurrentHashMap JDK1.8实现的原理是什么? 数组+链表+红黑树,CAS
ConcurrentHashMap JDK1.7中Segment数(concurrencyLevel)默认值是多少? 为何一旦初始化就不可再扩容?
ConcurrentHashMap JDK1.7说说其put的机制?
ConcurrentHashMap JDK1.7是如何扩容的? rehash(注:segment 数组不能扩容,扩容是 segment 数组某个位置内部的数组 HashEntry<K,V>[] 进行扩容)
ConcurrentHashMap JDK1.8是如何扩容的? tryPresize
ConcurrentHashMap JDK1.8链表转红黑树的时机是什么? 临界值为什么是8?
ConcurrentHashMap JDK1.8是如何进行数据迁移的? transfe
ConcurrentHashMap加锁原理 JDK1.8 1.8只有1个table(Map.Entry数组),同步机制为CAS + synchronized保证并发更新。
1.8放弃了Segment,直接用Node数组+链表+红黑树的数据结构来实现,并发控制使用Synchronized + CAS来实现更细粒度的锁保护,整个看起来就像是优化过且线程安全的HashMap。
取消segments字段,采用table数组元素作为锁(使用synchronized锁住),从而实现了对每一行数据进行加锁,进一步减少并发冲突的概率。
JDK1.7 1.7是使用segements(16个segement),每个segement都有一个table(Map.Entry数组),相当于16个HashMap,同步机制为分段锁,每个segment继承ReentrantLock。
ConcurrentHashMap 是由Segment 数组结构 + HashEntry 数组结构 + 链表组成。
put操作时,先获取锁 tryLock(),根据 key 的 hash 值 定位到 Segment ,再根据 key 的 hash 值 找到具体的 HashEntry ,再进行插入或覆盖,最后释放锁。
Segment数组的意义就是将一个大的table分割成多个小的table来进行加锁,也就是上面的提到的锁分离技术,而每一个Segment元素存储的是HashEntry数组+链表,这个和HashMap的数据存储结构一样。
ConcurrentHashMap - JDK 1.8 在JDK1.7之前,ConcurrentHashMap是通过分段锁机制来实现的,所以其最大并发度受Segment的个数限制。数组+链表+红黑树 的方式实现,而加锁则采用CAS和synchronized实现 。
数据结构
结构上和Java 8的HashMap基本上一样,不过它要保证线程安全,所以在源码上要复杂一些。
默认值 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 private static final int MAXIMUM_CAPACITY = 1 << 30 ;private static final int DEFAULT_CAPACITY = 16 ;static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8 ;private static final int DEFAULT_CONCURRENCY_LEVEL = 16 ;private static final float LOAD_FACTOR = 0.75f ;static final int TREEIFY_THRESHOLD = 8 ;static final int UNTREEIFY_THRESHOLD = 6 ;static final int MIN_TREEIFY_CAPACITY = 64 ;private static final int MIN_TRANSFER_STRIDE = 16 ;private static final int RESIZE_STAMP_BITS = 16 ;private static final int MAX_RESIZERS = (1 << (32 - RESIZE_STAMP_BITS)) - 1 ;private static final int RESIZE_STAMP_SHIFT = 32 - RESIZE_STAMP_BITS;static final int MOVED = -1 ; static final int TREEBIN = -2 ; static final int RESERVED = -3 ; static final int HASH_BITS = 0x7fffffff ; static final int NCPU = Runtime.getRuntime().availableProcessors();transient volatile Node<K,V>[] table;private transient volatile Node<K,V>[] nextTable;private transient volatile long baseCount;private transient volatile int sizeCtl;private transient volatile int transferIndex;private transient volatile int cellsBusy; private transient volatile CounterCell[] counterCells;
初始化 1 2 3 4 5 6 7 8 9 10 11 12 public ConcurrentHashMap () } public ConcurrentHashMap (int initialCapacity) if (initialCapacity < 0 ) throw new IllegalArgumentException(); int cap = ((initialCapacity >= (MAXIMUM_CAPACITY >>> 1 )) ? MAXIMUM_CAPACITY : tableSizeFor(initialCapacity + (initialCapacity >>> 1 ) + 1 )); this .sizeCtl = cap; }
这个初始化方法有点意思,通过提供初始容量,计算了 sizeCtl,sizeCtl = 【 (1.5 * initialCapacity + 1),然后向上取最近的 2 的 n 次方】。
putVal put过程分析 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 public V put (K key, V value) return putVal(key, value, false ); } final V putVal (K key, V value, boolean onlyIfAbsent) if (key == null || value == null ) throw new NullPointerException(); int hash = spread(key.hashCode()); int binCount = 0 ; for (Node<K,V>[] tab = table;;) { Node<K,V> f; int n, i, fh; if (tab == null || (n = tab.length) == 0 ) tab = initTable(); else if ((f = tabAt(tab, i = (n - 1 ) & hash)) == null ) { if (casTabAt(tab, i, null , new Node<K,V>(hash, key, value, null ))) break ; } else if ((fh = f.hash) == MOVED) tab = helpTransfer(tab, f); else { V oldVal = null ; synchronized (f) { if (tabAt(tab, i) == f) { if (fh >= 0 ) { binCount = 1 ; for (Node<K,V> e = f;; ++binCount) { K ek; if (e.hash == hash && ((ek = e.key) == key || (ek != null && key.equals(ek)))) { oldVal = e.val; if (!onlyIfAbsent) e.val = value; break ; } Node<K,V> pred = e; if ((e = e.next) == null ) { pred.next = new Node<K,V>(hash, key, value, null ); break ; } } } else if (f instanceof TreeBin) { Node<K,V> p; binCount = 2 ; if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key, value)) != null ) { oldVal = p.val; if (!onlyIfAbsent) p.val = value; } } } } if (binCount != 0 ) { if (binCount >= TREEIFY_THRESHOLD) treeifyBin(tab, i); if (oldVal != null ) return oldVal; break ; } } } addCount(1L , binCount); return null ; }
1.8 中 ConcurrentHashMap put操作为什么用synchronized? 有两个原因:
减少内存开销
获得JVM的支持
初始化数组 initTable 初始化一个合适大小的数组,然后会设置 sizeCtl。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 private final Node<K,V>[] initTable() { Node<K,V>[] tab; int sc; while ((tab = table) == null || tab.length == 0 ) { if ((sc = sizeCtl) < 0 ) Thread.yield(); else if (U.compareAndSwapInt(this , SIZECTL, sc, -1 )) { try { if ((tab = table) == null || tab.length == 0 ) { int n = (sc > 0 ) ? sc : DEFAULT_CAPACITY; Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n]; table = tab = nt; sc = n - (n >>> 2 ); } } finally { sizeCtl = sc; } break ; } } return tab; }
链表转红黑树 treeifyBin 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 private final void treeifyBin (Node<K,V>[] tab, int index) Node<K,V> b; int n, sc; if (tab != null ) { if ((n = tab.length) < MIN_TREEIFY_CAPACITY) tryPresize(n << 1 ); else if ((b = tabAt(tab, index)) != null && b.hash >= 0 ) { synchronized (b) { if (tabAt(tab, index) == b) { TreeNode<K,V> hd = null , tl = null ; for (Node<K,V> e = b; e != null ; e = e.next) { TreeNode<K,V> p = new TreeNode<K,V>(e.hash, e.key, e.val, null , null ); if ((p.prev = tl) == null ) hd = p; else tl.next = p; tl = p; } setTabAt(tab, index, new TreeBin<K,V>(hd)); } } } } }
扩容 tryPresize 如果说 Java8 ConcurrentHashMap 的源码不简单,那么说的就是扩容操作 和迁移操作 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 private final void tryPresize (int size) int c = (size >= (MAXIMUM_CAPACITY >>> 1 )) ? MAXIMUM_CAPACITY : tableSizeFor(size + (size >>> 1 ) + 1 ); int sc; while ((sc = sizeCtl) >= 0 ) { Node<K,V>[] tab = table; int n; if (tab == null || (n = tab.length) == 0 ) { n = (sc > c) ? sc : c; if (U.compareAndSwapInt(this , SIZECTL, sc, -1 )) { try { if (table == tab) { @SuppressWarnings("unchecked") Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n]; table = nt; sc = n - (n >>> 2 ); } } finally { sizeCtl = sc; } } } else if (c <= sc || n >= MAXIMUM_CAPACITY) break ; else if (tab == table) { int rs = resizeStamp(n); if (sc < 0 ) { Node<K,V>[] nt; if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 || sc == rs + MAX_RESIZERS || (nt = nextTable) == null || transferIndex <= 0 ) break ; if (U.compareAndSwapInt(this , SIZECTL, sc, sc + 1 )) transfer(tab, nt); } else if (U.compareAndSwapInt(this , SIZECTL, sc, (rs << RESIZE_STAMP_SHIFT) + 2 )) transfer(tab, null ); } } }
数据迁移 transfer get过程分析 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 public V get (Object key) Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek; int h = spread(key.hashCode()); if ((tab = table) != null && (n = tab.length) > 0 && (e = tabAt(tab, (n - 1 ) & h)) != null ) { if ((eh = e.hash) == h) { if ((ek = e.key) == key || (ek != null && key.equals(ek))) return e.val; } else if (eh < 0 ) return (p = e.find(h, key)) != null ? p.val : null ; while ((e = e.next) != null ) { if (e.hash == h && ((ek = e.key) == key || (ek != null && key.equals(ek)))) return e.val; } } return null ; } static final <K,V> Node<K,V> tabAt (Node<K,V>[] tab, int i) { return (Node<K,V>)U.getObjectVolatile(tab, ((long )i << ASHIFT) + ABASE); }
get过程:
计算 hash 值
根据 hash 值找到数组对应位置: (n - 1) & h
根据该位置处结点性质进行相应查找
如果该位置为 null,那么直接返回 null 就可以了
如果该位置处的节点刚好就是我们需要的,返回该节点的值即可
如果该位置节点的 hash 值小于 0,说明正在扩容,或者是红黑树,后面我们再介绍 find 方法
如果以上 3 条都不满足,那就是链表,进行遍历比对即可
JDK 1.8 ConcurrentHashMap 读操作为什么不用加锁? 读的时候如果不是恰好读到写线程写入相同Hash值的位置(可以认为我们的操作一般是读多写少,这种几率也比较低)get 方法会调用 tabAt 方法,这是一个Unsafe类volatile的操作,保证每次获取到的值都是最新的。(强制将修改的值立即写入主存)
ConcurrentHashMap - JDK 1.7 在JDK1.5~1.7版本,Java使用了分段锁机制实现ConcurrentHashMap。
数据结构 整个 ConcurrentHashMap 由一个个 Segment 组成,Segment 代表”部分“或”一段“的意思,所以很多地方都会将其描述为分段锁。注意,行文中,我很多地方用了槽 来代表一个 segment。
简单理解就是,ConcurrentHashMap 是一个 Segment 数组,Segment 通过继承 ReentrantLock 来进行加锁,所以每次需要加锁的操作锁住的是一个 segment,这样只要保证每个 Segment 是线程安全的,也就实现了全局的线程安全。
concurrencyLevel: 并行级别、并发数、Segment 数,怎么翻译不重要,理解它。默认是 16 ,也就是说 ConcurrentHashMap 有 16 个 Segments。所以理论上,这个时候,最多可以同时支持 16 个线程并发写,只要它们的操作分别分布在不同的 Segment 上。一旦初始化以后,它是不可以扩容的 。
再具体到每个 Segment 内部,其实每个 Segment 很像之前介绍的 HashMap,不过它要保证线程安全,所以处理起来要麻烦些。