ElasticSearch-数据同步方案
数据同步类型
- 增量同步
ES服务接入后,MySQL数据库数据实时增量同步至ES中。 - 全量同步
ES服务接入时,将MySQL中的历史数据优雅切完整的置入ES中。
数据同步方案
1. 同步双写
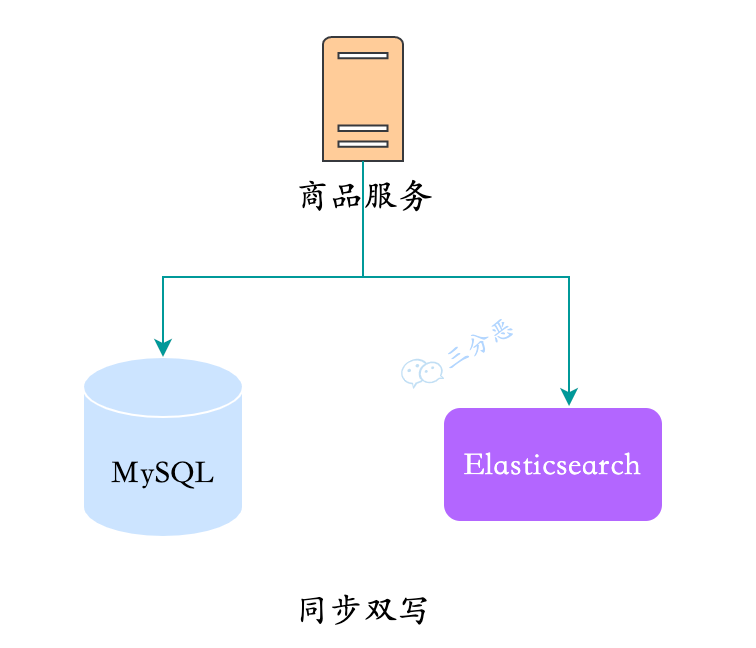
- 优点
实现最简单,新增、更新、删除时,写入数据库同时写入ES。 - 缺点
- 业务逻辑耦合度高,耦合大量数据同步代码;
- 写入两个存储,接口的响应时间变长;
- 不便于扩展,搜索可能会有一些个性化需求,需要对数据进行聚合。
2. ES服务订阅消息队列,异步写入
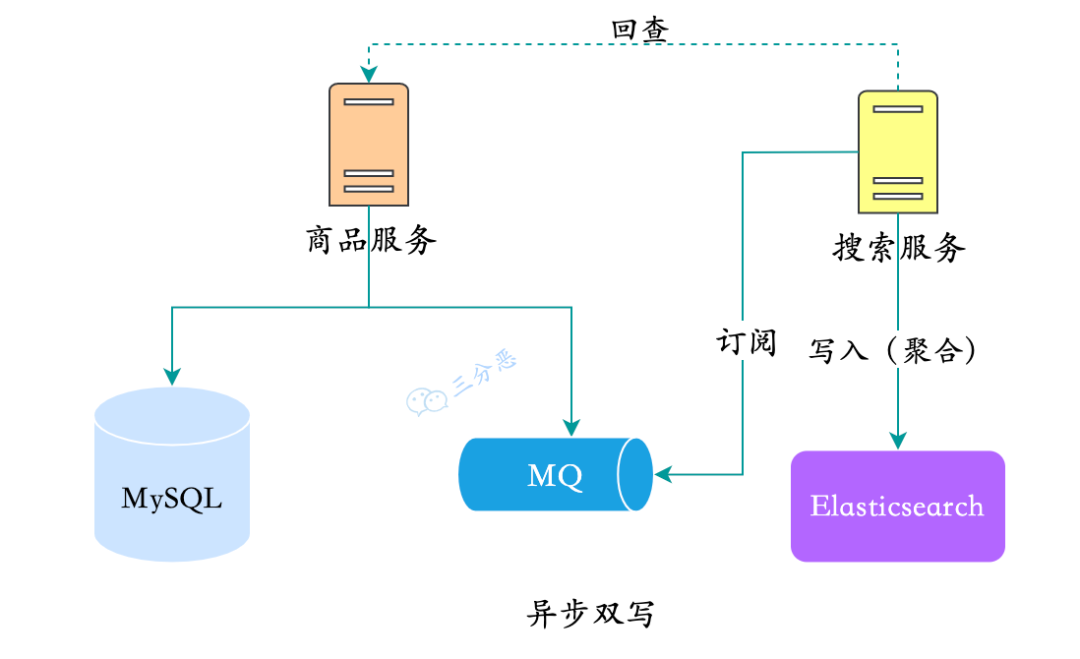
业务数据有变动的时候,将数据丢进MQ。为了解耦合,一般会拆分一个搜索服务,由搜索服务去订阅数据变动的消息,来完成同步。
一般数据需要聚合处理成类似宽表的结构,搜索服务需要查库或者远程调用接口,回查来完成数据的聚合。
- 优点
- 解耦合,业务服务不需要关注数据同步
- 实时性较好,适用MQ,正常情况下,同步完成在秒级
- 缺点
引入了新的组件和服务,复杂度提升
3. 定时任务
如果数据量不大,需要快速搞搞实现的话,可以选择定时任务的方式。
- 优点:不改变原来的代码,侵入性低,没有业务强耦合。
- 缺点:时效性差,定时任务的执行周期不好设定;需要频繁的查询数据库,给数据库增加一定的压力。
具体实现
- 近实时update任务
定时任务按较短的时间周期,读取UpdateTime大于上一次读取时间的所有数据,即该段时间内的增量,将这些数据写入到es,然后更新定时任务中的UpdateTime标识,重复执行。 - 全量修复任务
每小时全量对比修复一次数据。
4. 数据订阅,基于 MySQL binlog
MySQL 通过 binlog 订阅实现主从同步,各路数据订阅框架比如 canal 就依据这个原理,将 client 组件伪装成从库,来实现数据订阅。
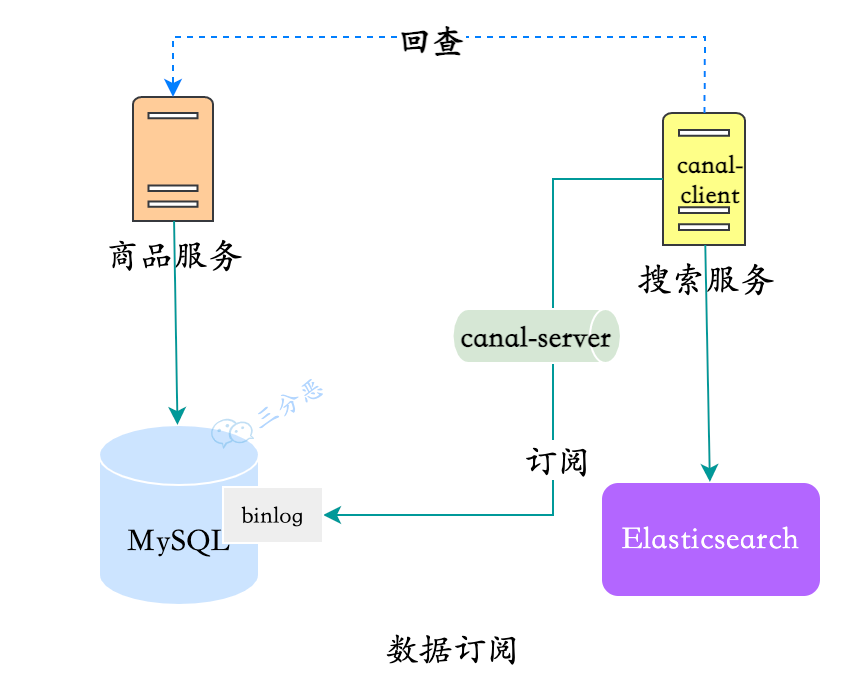
借助canal,实现canal-client,监听和聚合数据,写入ES。
基于 MySQL Binlog 的 Elasticsearch 数据同步实践
基于MySQL binlog日志,实现Elasticsearch近实时同步实践
问题
实时性要求高的场景,ES如何使用
ES索引数据写入过程:write -> refresh -> flush -> merge。
新增数据时,会先写入到ES用户进程的内存缓冲区,然后定时(默认是每隔1秒)写入到操作系统(内核态)的缓存,然后由操作系统决定刷盘时机,数据落入磁盘。
当数据写入到操作系统的缓存,数据就可以被搜索到。所以ES是近实时搜索,而非实时。文档的变化并不是立即对搜索可见,但会在一秒之内变为可见。
如果业务系统的ES对于refresh是配置为默认1秒或者大于1秒,对于实时性要求高的业务,数据的准确性会有问题。