数据结构与算法——复杂度分析
什么是复杂度分析?
1.数据结构和算法解决“如何让计算机更快时间、更省空间的解决问题”。
2.因此需要从执行时间和占用空间两个维度来评估数据结构和算法的性能。
3.分别用时间复杂度和空间复杂度两个概念来描述性能问题,二者统称为复杂度。
4.复杂度描述的是算法执行时间(或占用空间)与数据规模的增长关系。
为什么要进行复杂读分析?
1.和性能测试相比,复杂度分析有不依赖执行环境、成本低、效率高、易操作、指导性强的特点。
2.掌握复杂度分析,将能编写出性能更优的代码,有利于降低系统开发和维护成本。
如何进行复杂度分析?
大O表示法
1.来源
算法的执行时间与每行代码的执行次数成正比,用T(n)=O(f(n))表示,其中T(n)表示算法执行总时间,f(n)表示每行代码执行总次数,而n往往代表数据的规模。
2.特点
以时间复杂度为例,由于时间复杂度描述的是算法执行时间与数据规模的增长变化趋势,所以常量阶、低阶以及系数实际上对这种增长趋势不产生决定性影响,所以在做时间复杂度分析时忽略这些项。
复杂度分析法则
1.单段代码看高频。比如循环。
2.多段代码取最大。比如一段代码中有单循环和多重循环,那么取多重循环的复杂度。
3.嵌套代码求乘积。比如递归、多重循环等。
4.多个规模求加法。比如方法有两个参数(m、n)控制两个循环的次数,那么这时就取二者复杂度相加。
常用的复杂度级别
多项式阶
随着数据规模的增长,算法的执行时间和空间占用,按照多项式的比例增长。包括:O(1)(常数阶)、O(logn)(对数阶)、O(n)(线性阶)、O(nlogn)(线性对数阶)、O(n^2)(平方阶)、O(n^3)(立方阶)。
非多项式阶
随着数据规模的增长,算法的执行时间和空间占用暴增,这类算法性能极差。包括O(2^n)(指数阶)、O(n!)(阶乘阶)。
复杂度也叫渐进复杂度,包括时间复杂度和空间复杂度,用来分析算法执行效率和数据规模之间的增长关系。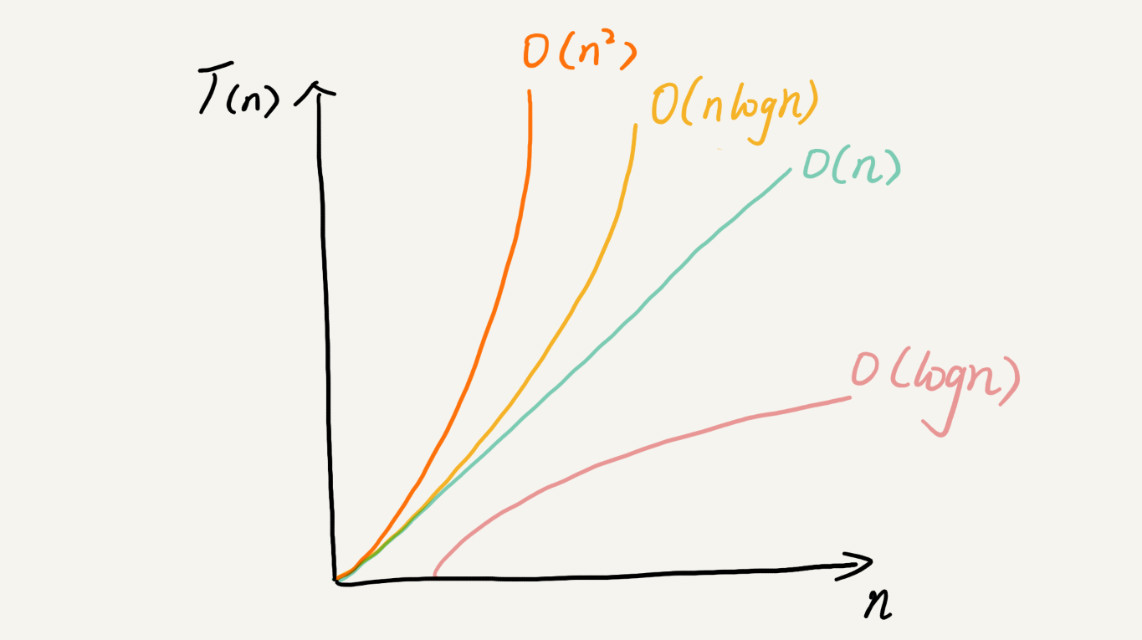
复杂度分析的四个概念
1 | // n 表示数组 array 的长度 |
这段代码要实现的功能是,在一个无序的数组(array)中,查找变量x出现的位置。如果没有找到,就返回-1。这段代码的复杂度看上去的话是O(n)。
最好情况时间复杂度
代码在最理想情况下执行的时间复杂度。
在最理想的情况下,要查找的变量x正好是数组的第一个元素,这个时候对应的时间复杂度就是最好情况时间复杂度。
最坏情况时间复杂度
代码在最坏情况下执行的时间复杂度。
如果数组中没有要查找的变量x,需要把整个数组都遍历一遍。
平均情况时间复杂度
用代码在所有情况下执行的次数的加权平均值表示。
要查找的变量x,要么在数组中,要么就不在数组里,这两种情况对应的概率统计起来很麻烦,假设在数组中与不在数组中的概率都为1/2。另外,要查找的数据出现在0n-1这n个位置的概率也是一样的,为1/n。所以根据概率乘法法则,要查找的数据出现在0n-1中任意位置的概率就是1/(2n)。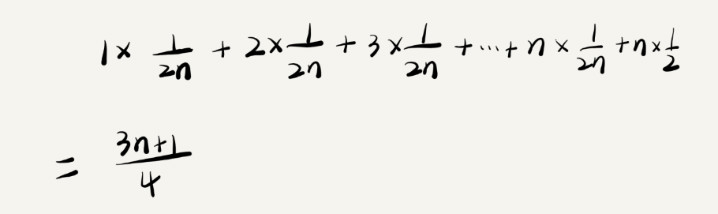
这个值是概率论中的加权平均值,也叫做期望值,所以平均时间复杂度的全称应该叫做加权平均时间复杂度或者期望时间复杂度。
引入概率之后,前面那段代码的加权平均值为(3n+1)/4,用大O表示法来表示,去掉系数和常量,仍然为O(n)。
均摊时间复杂度
1 | // array 表示一个长度为 n 的数组 |
这段代码实现一个往数组中插入数据的功能。当数组满了之后,count==array.length时,我们用for循环遍历数组求和,并清空数组,将求和之后的sum值放到数组的第一个位置,然后将新的数据插入。但如果数组一开始就有空闲空间,则直接将数据插入数组。
时间复杂度最好为O(1),最坏为O(n),平均时间复杂度也是O(1)。
假设数组的长度是n,根据数据插入的位置不同,分为n种情况,每种情况的时间复杂度是O(1),另外在数组没有空闲空间时插入一个数据,这时是O(n),这n+1种情况发生的改率一样,都是1/(n+1)。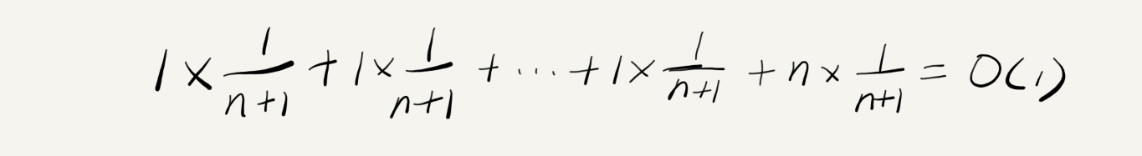
对于后面这个inset()函数来说,O(1)和O(n)出现的频率是有规律的,而且有一定的前后时序关系,一般都是一个O(n)插入之后,紧跟着n-1个O(1)的插入操作,循环往复。
针对这种特殊场景,引入一种更加简单的分析方法:摊还分析法,通过摊还分析得到均摊时间复杂度。
均摊时间复杂度是一种特殊的平均时间复杂度。
对一个数据结构进行一组连续操作中,大部分情况下时间复杂度都很低,只有个别情况下时间复杂度比较高,而且这些操作之间存在前后连贯的时序关系,这时候,可以将这一组操作放在一块儿分析,将较高时间复杂度那次操作的耗时,平摊到其他那些时间复杂度比较低的操作上。而且在能够应用均摊时间复杂度分析的场合,一般均摊时间复杂度等于最好情况时间复杂度。