微服务-服务调用-Dubbo
Q&A
https://zhuanlan.zhihu.com/p/366350188
让你设计一个RPC框架你怎么设计?
RPC 框架基础的核心其实就这么几点:- 动态代理(屏蔽底层调用细节)
- 序列化(网络数据传输需要扁平的数据)
- 协议(规定协议,才能识别数据)
- 网络传输(I/O模型BB一下,一般用 Netty 作为底层通信框架即可)
从底层向上说起:
- 首先需要实现高性能的网络传输,可以采用Netty来实现;然后需要自定义协议,毕竟远程交互都需要遵循一定的协议,然后还需要定义好序列化协议,网络的传输毕竟都是二进制流传输的;
- 然后可以搞一套描述服务的语言,即IDL(Interface description language),让所有的服务都用IDL定义,再由框架转换为特定编程语言的接口,这样就能跨语言了;
- 框架需要把上述的底层细节对使用者进行屏蔽,让使用者感受不到本地调用和远程调用的区别,所以需要代理实现;
- 然后还需要实现集群功能、注册中心;
- 完善的监控机制,埋点上报调用情况等等,便于运维。
Dubbo 是用来做什么的?内部的大概原理能讲一下吗?
Dubbo 的提供者核心源码和原理:
- 服务提供者是如何将自己的服务暴露出去的,然后消费者为什么能调用?
Dubbo 提供者是如何暴露服务的呢,其实就是干了两件事:一个是将提供者的信息注册到注册中心,一个是启动 NettyServer 作为服务端提供服务。
- Dubbo 的消费者核心源码和原理:
- 服务消费者是如何仅仅通过一个接口类直接调用到提供者的,并且做到失败重试、负载均衡的?
- Netty:Dubbo 是使用 Netty 作为通信框架,那么使用 Netty 有什么好处?
- 编解码器如何处理粘包和拆包,如何解决 TCP 网络传输中的拆包和粘包?
拆包是指在网络传输过程中,一份数据被拆分为多次传输,每次只传输了一部分。
粘包是指在网络传输中,两份数据合并在一起传输过去了。
Dubbo 的网络拆包和粘包的处理是通过在 Netty 的处理链条中添加的编解码器实现的。 Dubbo 的编码器是 DubboCodec 的父类 ExchangeCodec 实现的。
Dubbo - 架构
核心角色
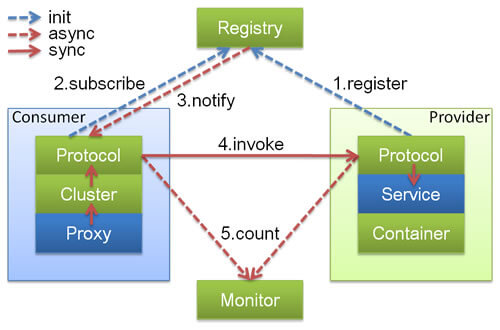
结合上图说下Dubbo的基本工作流程,主要分为四步:
- Provider向注册中心注册服务信息,包括Provider的IP和端口;
- Consumer从注册中心订阅提供者服务,注册中心会返回服务提供者地址列表给消费者;
- Consumer通过服务URL调用Provider;
- Consumer和Provider异步上报统计信息给监控中心。
注册中心、服务提供者、服务消费者三者之间均为长连接(默认情况下分别只有1个长连接,因为consume和provider网络连接都使用了IO复用,性能上还是OK的)。
注册中心通过长连接感知服务提供者的存在,服务提供者宕机,注册中心将立即推送事件通知消费者。
注册中心和监控中心全部宕机,不影响已运行的提供者和消费者,消费者在本地缓存了提供者列表。
注册中心和监控中心都是可选的,服务消费者可以直连服务提供者。
Invoker模型
Invoker是 Dubbo 领域模型中非常重要的一个概念。简单来说,Invoker 就是 Dubbo 对远程调用的抽象。
- 任何框架或组件,总会有核心领域模型,比如Spring的Bean、Dubbo的Service,这个核心领域模型及其组成部分称为实体域,它代表着我们要操作的目标本身。
- 服务域也就是行为域,它是组件的功能集,同时也负责实体域和会话域的生命周期管理,比如Spring的ApplicationContext、Dubbo的ServiceManager。
- 会话,就是一次交互过程。会话中的重要概念是上下文。
- 把元信息交由实体域持有,把一次请求中的临时状态由会话域持有,由服务域贯穿整个过程。
Invoker是Dubbo中的实体域,也就是真实存在的。其他模型都向它靠拢或转换成它,它也就代表一个可执行体,可向它发起invoke调用。
在服务消费方,Invoker用于执行远程调用。
在服务提供方,Invoker用于调用服务提供类。
Invoker在RPC过程中的作用
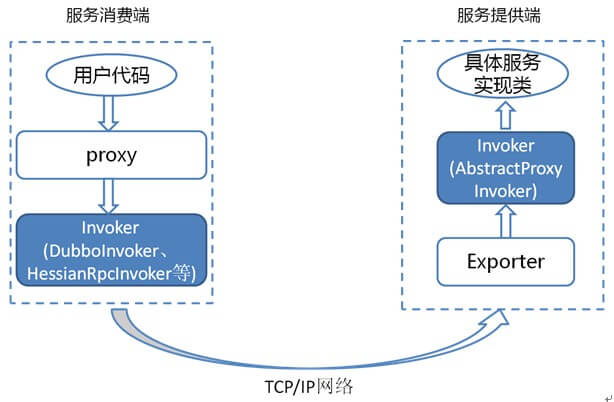
在服务提供方中,Invoker封装了具体的服务实现类。
当服务消费方需要通过RPC调用这个服务时,生成proxy调用服务消费方的Invoker,借助网络通知到服务提供方的Exporter,然后Exporter调用服务提供方的Invoker执行具体的服务逻辑。
可以看出,Invoker实质上就是由动态代理生成并封装了网络连接和数据处理的逻辑,以屏蔽底层的实现,这就是Dubbo动态代理技术的实际实现了。
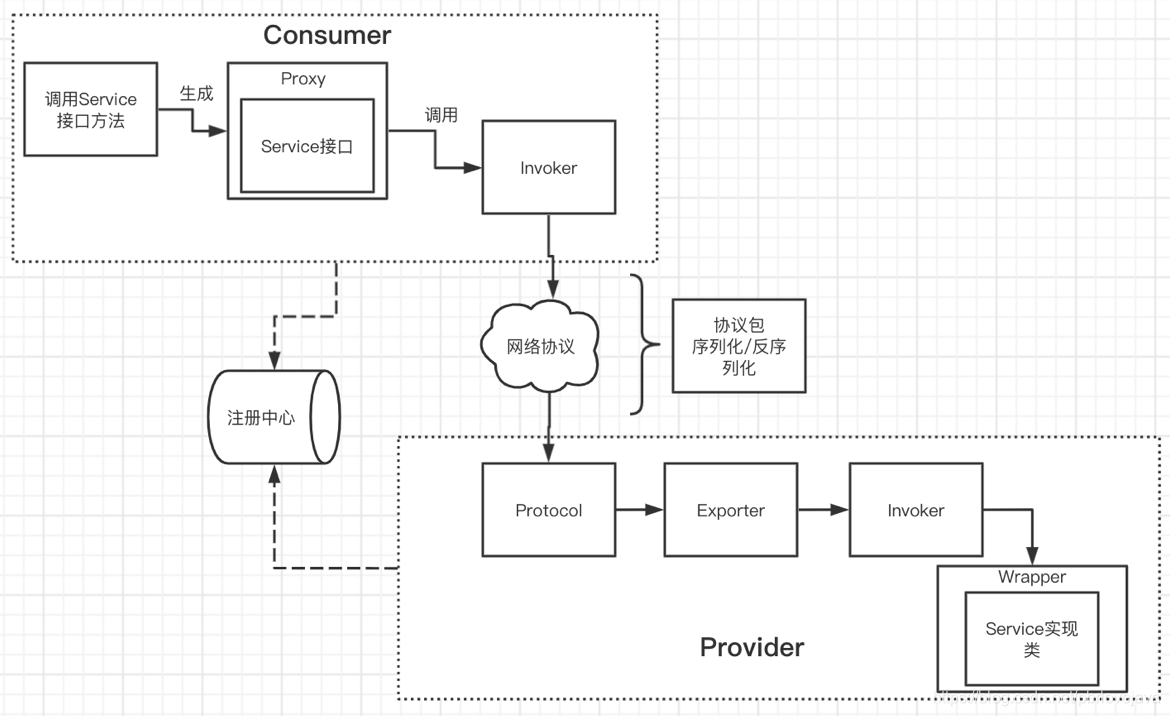
服务消费方的Invoker
在服务消费方,Invoker用于执行远程调用。
服务消费方的Invoker是由Protocol实现类构建而来的基于Netty的客户端。
Protocol实现类有很多但是最常用的两个,分别是RegistryProtocol和DubboProtocol。
- DubboProtocol的refer方法 最重要的一个在于
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
public <T> Invoker<T> refer(Class<T> type, URL url) throws RpcException {
checkDestroyed();
return protocolBindingRefer(type, url);
}
public <T> Invoker<T> protocolBindingRefer(Class<T> serviceType, URL url) throws RpcException {
checkDestroyed();
optimizeSerialization(url);
// create rpc invoker.
// 创建 DubboInvoker - getClients(url)
DubboInvoker<T> invoker = new DubboInvoker<T>(serviceType, url, getClients(url), invokers);
invokers.add(invoker);
return invoker;
}getClients,这个方法用于获取服务消费端实例,实例类型为ExchangeClient。ExchangeClient实际上并不具备通信能力,它需要基于更底层的客户端实例进行通信,比如NettyClient、MinaClient等,默认情况下,Dubbo使用NettyClient进行通信。每次创建好的Invoker都会添加到invokers这个集合里。也就是可以认为服务消费方的Invoker是一个具有通信能力的Netty客户端。
服务提供方的Invoker
在服务提供方,Invoker用于调用服务提供类。
在服务提供方中的Invoker是由ProxyFactory创建而来的服务类的实例,可以实现调用服务类内部的方法和修改字段。
Dubbo默认的ProxyFactory实现类为JavassistProxyFactory。
工作原理
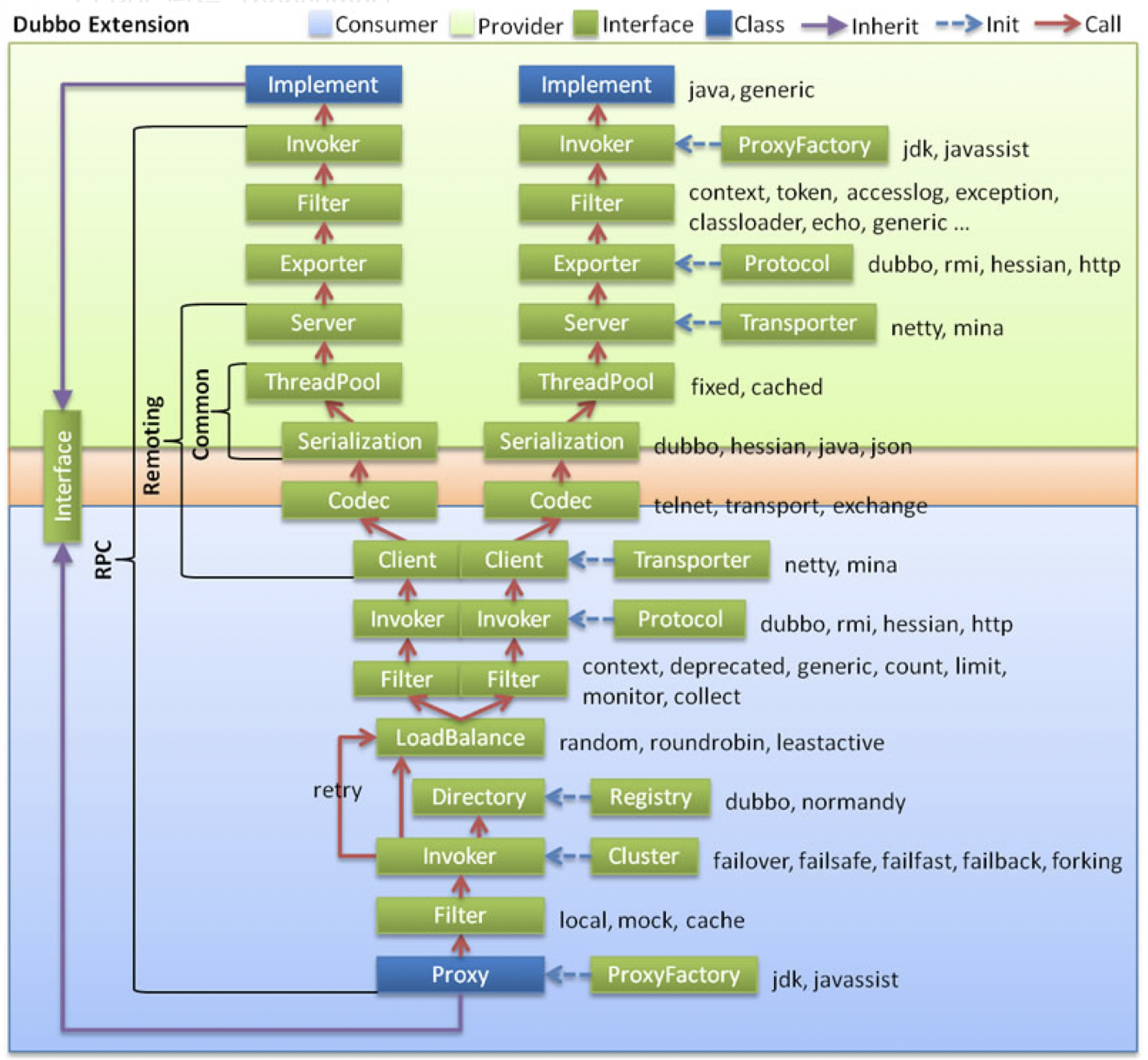
下图是 Dubbo 的整体设计,从下至上分为十层,各层均为单向依赖。
左边淡蓝背景的为服务消费方使用的接口,右边淡绿色背景的为服务提供方使用的接口,位于中轴线上的为双方都用到的接口。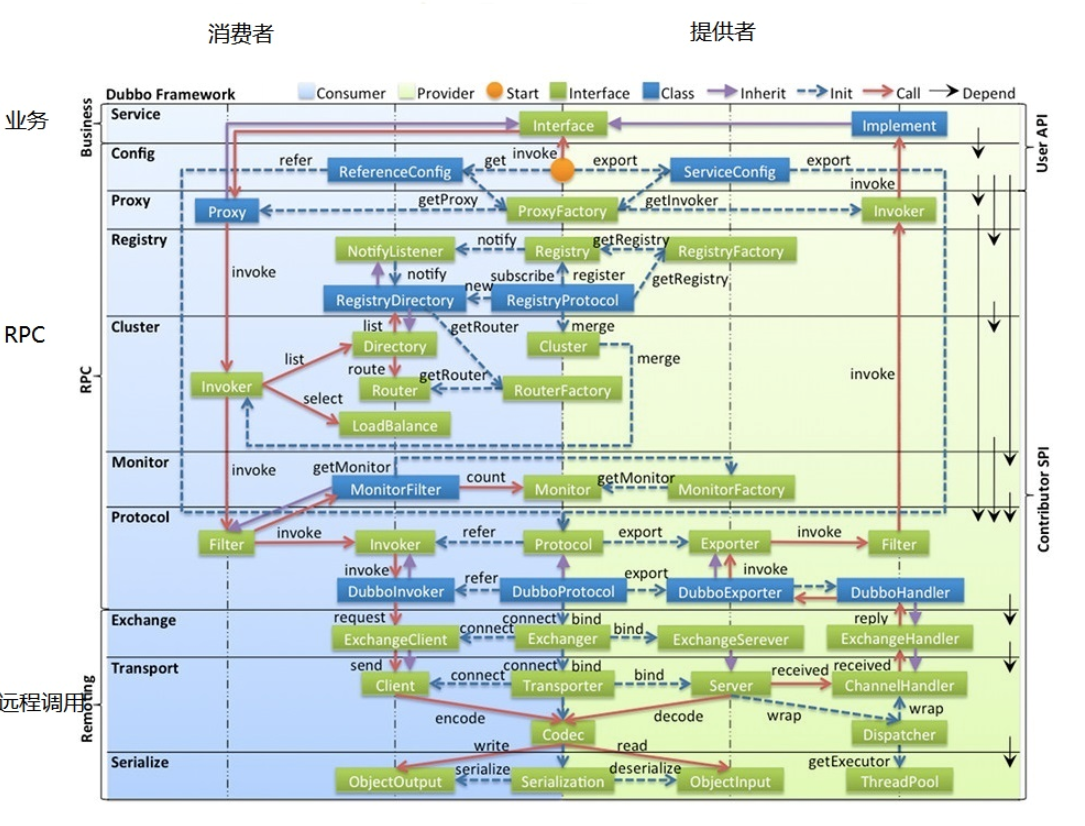
各层说明
- config 配置层
Dubbo相关的配置。支持代码配置,同时也支持基于 Spring 来做配置,以ServiceConfig(服务提供者)、ReferenceConfig(服务消费者) 为中心。 - proxy 服务代理层
调用远程方法像调用本地的方法一样简单的一个关键,真实调用过程依赖代理类,以ServiceProxy为中心。 - registry 注册中心层
负责服务的注册与发现。 - cluster 集群、路由层
封装多个服务提供者的路由以及负载均衡,将多个实例组合成一个服务。 - monitor 监控层
- protocol 远程调用层
封装rpc调用,以Invocation和Result为中心,扩展接口为Protocol、Invoker和Exporter。
Protocol是服务域,它是Invoker暴露和引用的主功能入口,它负责Invoker的生命周期管理。
Invoker是实体域,它是Dubbo的核心模型,其它模型都向它靠扰,或转换成它,它代表一个可执行体,可向它发起invoke调用,它有可能是一个本地的实现,也可能是一个远程的实现,也可能一个集群实现。 - exchange 信息交换层
封装请求响应模式,同步转异步。
服务提供者通过Exchanger来bind,从而创建一个NettyServer。
服务消费者通过Exchanger来connect,从而创建一个NettyClient。 - transport 网络传输层
抽象mina和netty为统一接口,以 Message 为中心,扩展接口为Channel、Transporter、Client、Server、Codec。 - serialize 数据序列化层
网络传输需要,对需要在网络传输的数据进行序列化。
调用流程
- 服务提供者启动,启动NettyServer作为服务端提供服务,向注册中心注册提供者服务。
- 服务消费者启动,通过注册中心,将接口类的提供者信息拉取到本地缓存起来,并且监听该接口类的提供者列表的变更事件。
- 服务消费者通过接口开始远程调用服务:
- ProxyFactory通过初始化Proxy对象,Proxy通过创建动态代理对象。
- 动态代理对象通过invoke方法,层层包装生成一个Invoker对象,该对象包含了代理对象。
- Invoker通过路由、负载均衡选择了一个最合适的服务提供者,再通过加入各种过滤器,协议层包装生成一个新的DubboInvoker对象。
- 再通过交换层将DubboInvoker对象包装成一个Reuqest对象,该对象经过编码、序列化,由服务消费者的NettyClient端传输到服务提供者的NettyServer端。
- 到了服务提供者这边:
- 通过反序列化、协议解密等操作生成一个DubboExporter对象,再层层传递处理,会生成一个服务提供端的Invoker对象。
- 这个Invoker对象会调用本地服务,获得结果再通过层层回调返回到服务消费者,服务消费者拿到结果后,再解析获得最终结果。
深入理解:dubbo是如何与Spring整合的
深入理解:服务提供方
provider是如何启动的
https://luoxn28.github.io/2020/07/11/dubbo-provider-shi-ru-he-qi-dong-de/
以netty4的NettyServer为例。
ServiceBean @DubboService
Dubbo RPC在provider端是如何跑起来的
深入理解:服务消费方
consumer是如何启动的
ReferenceBean @DubboReference
Dubbo RPC在consumer端是如何跑起来的
由于RPC流程涉及consumer和provider端,先来看一下在二者之间RPC流程的线程模型图,有个初步认识: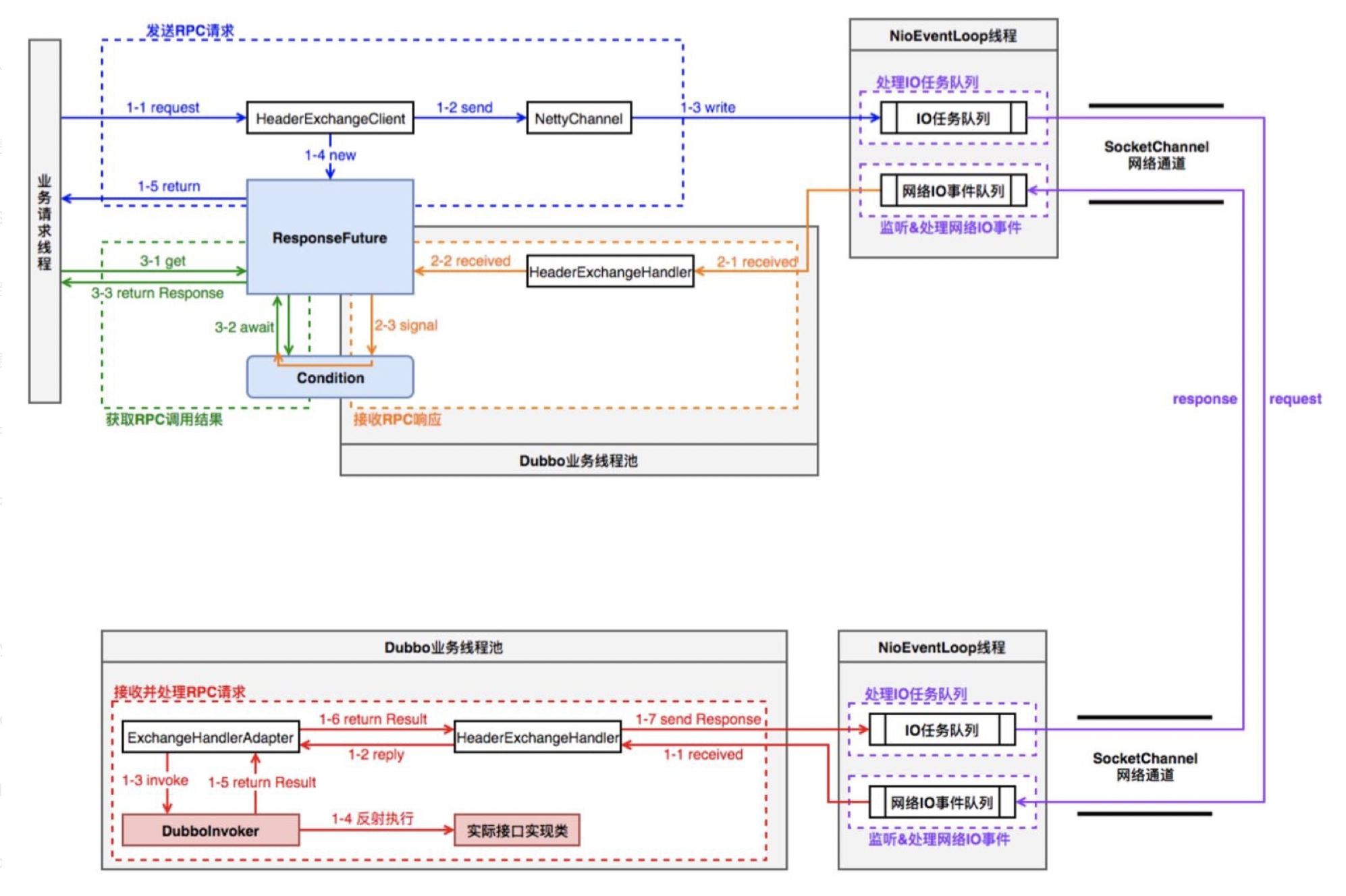
以如下consumer端代码为例开始进行讲解:
1 | DemoService demoService = (DemoService) context.getBean("demoService"); // get remote service proxy |
当consumer端调用一个@Reference的RPC服务,在consumer端的cluster层首先从Driectory中获取invocation对应的invokerList,经过Router过滤符合路由策略的invokerList,然后执行LoadBalance,选择出某个Invoker,最后进行RPC调用操作。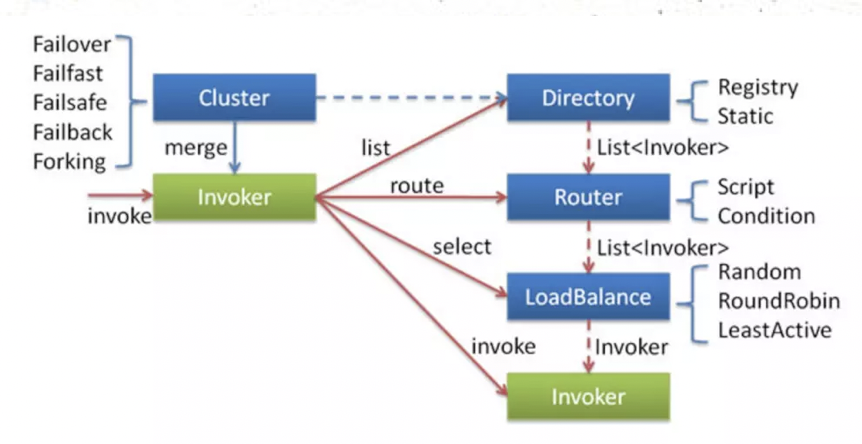
调用某个Invoker(经过cluter之后)进行RPC时,依次会经过Filter、DubboInvoker、HeaderExchangeClient,将RPC消息类RPCInvocation传递到netty channel.eventLoop中。最后由netty Channel经过Serializer之后将RPC请求发送给provider端。
- 集群容错
Dubbo提供了多种容错方案,默认模式为Failover Cluster,也就是失败重试。 - Directory
Directory是RPC服务类的目录服务,一个服务接口对应一个Directory实例。 - Router
Router是RPC的路由策略,通过Directory获取到invokerList之后,会执行对应的路由策略。
Dubbo的默认路由策略是MockInvokersSelector。 - LoadBalance
LoadBalance是RPC的负载均衡策略,通过Directory获取到invokerList并且执行对应的路由策略之后,就会执行LoadBalance(负载均衡)了。- RandomLoadBalance,随机选择,Dubbo的默认策略。
- RoundRobinLoadBalance,轮询
- LeastActiveLoadBalance,最少活跃数
- ConsistentHashLoadBalance,一致性hash
- Filter处理
- DubboInvoker
DubboInvoker的主要逻辑就是从provider的长连接中选择某个连接,然后根据不同的策略(同步/异步/单向)来进行操作。最后会调用channel.writeAndFlush,之后的流程就是netty channel内部的处理流程了,后续流程会走到我们设定的NettyHandler中对应的方法中,比如channel.write就会走到NettyHandler.writeRequested方法中逻辑,也就是针对RPC请求数据进行序列化操作。1
2
3
4// DubboInvoker
protected Result doInvoke(final Invocation invocation) throws Throwable {
} - RPC结果处理
接收到provider端返回的RPC结果进行反序列化之后,就该将结果数据提交到consuemr端dubbo业务线程池了。
深入理解:Dubbo的线程模型
https://luoxn28.github.io/2020/07/05/dubbo-xian-cheng-mo-xing/
Dubbo中线程池的应用还是比较广泛的,按照consumer端到provider的RPC的方向来看,consumer端的应用业务线程到netty线程、consuemr端dubbo业务线程池,到provider端的netty boss线程、worker线程和dubbo业务线程池等。这些线程各司其职相互配合,共同完成dubbo RPC服务调用,理解dubbo线程模型对于学习Dubbo原理很有帮助。
线程模型策略
Dubbo默认的底层网络通信使用的是Netty,服务提供方NettyServer使用两级线程池,其中EventLoopGroup(boss)主要用来接收客户端的链接请求,并把完成TCP三次握手的连接分发给EventLoopGroup(worker)来处理,注意把boss和worker线程组称为I/O线程,前者处理IO连接事件,后者处理IO读写事件。
线程池策略
深入理解:Dubbo的连通性
关于dubbo连通性,也就是dubbo各组件之间通信、provider和consumer连接、以及通信方式这些功能点。
长连接
Dubbo 缺省协议采用单一长连接和 NIO 异步通讯,适合于小数据量大并发的服务调用,以及服务消费者机器数远大于服务提供者机器数的情况。
反之,Dubbo 缺省协议不适合传送大数据量的服务,比如传文件,传视频等,除非请求量很低。
默认使用netty+hessian2通信,基于TCP传输协议。
Dubbo - 机制
Dubbo中的SPI机制
SPI(Service Provider Interface) 机制被大量用在开源项目中,它可以帮助我们动态寻找服务/功能(比如负载均衡策略)的实现。
SPI 的具体原理是这样的:我们将接口的实现类放在配置文件中,我们在程序运行过程中读取配置文件,通过反射加载实现类。这样,我们可以在运行的时候,动态替换接口的实现类。和 IoC 的解耦思想是类似的。
Dubbo 并未使用Java SPI,而是重新实现了一套功能更强的SPI 机制。
Dubbo SPI 的相关逻辑被封装在了ExtensionLoader 类中,通过ExtensionLoader,我们可以加载指定的实现类。
Dubbo SPI 所需的配置文件需放置在META-INF/dubbo 路径下,与Java SPI 实现类配置不同,DubboSPI 是通过键值对的方式进行配置。
如何扩展Dubbo中的默认实现?
比如说我们想要实现自己的负载均衡策略,我们创建对应的实现类 XxxLoadBalance 实现 LoadBalance 接口或者继承AbstractLoadBalance 类。
1 | package com.xxx; |
将这个实现类的路径写入到resources 目录下的 META-INF/dubbo/org.apache.dubbo.rpc.cluster.LoadBalance文件中即可。
Dubbo中的动态编译
在Dubbo 中,很多拓展都是通过SPI 机制 进行加载的,比如Protocol、Cluster、LoadBalance、ProxyFactory 等。
有时,有些拓展并不想在框架启动阶段被加载,而是希望在拓展方法被调用时,根据运行时参数进行加载,即根据参数动态加载实现类。
这种在运行时,根据方法参数才动态决定使用具体的拓展,在dubbo中就叫做扩展点自适应实例。其实是一个扩展点的代理,将扩展的选择从Dubbo启动时,延迟到RPC调用时。Dubbo中每一个扩展点都有一个自适应类,如果没有显式提供,Dubbo会自动为我们创建一个,默认使用Javaassist。
自适应拓展机制的实现逻辑是这样的:
- 首先Dubbo 会为拓展接口生成具有代理功能的代码;
- 通过javassist 或jdk 编译这段代码,得到Class 类;
- 通过反射创建代理类;
- 在代理类中,通过URL对象的参数来确定到底调用哪个实现类;
Dubbo的微内核架构
从Dubbo的RPC调用链路中可以知道,Dubbo不变的地方涉及到服务的RPC调用和服务治理的一些概念与流程,但是对于每个环节又可以使用各种方式实现。
比如序列化机制可以是Json、Java序列化、Hession2或者Protobuf等等;网络传输层可以是netty实现的tcp通信,也可以使用http协议。
那Dubbo又是如何封装不变部分扩展这种可变部分呢?那就是接下来要说的微内核机制。
对于Apache Dubbo来说,变化的是RPC调用流程和微服务治理这些抽象的概念的具体实现,每个点应该用什么技术实现,又是用什么场景。
微内核架构由两大架构模块组成:核心系统与插件模块,设计一个微内核体系关键工作全部集中于核心系统怎么构建。
- 核心系统,负责和具体业务功能无关的通用功能,例如模块加载、模块间通信等,这个其实对应着Dubbo的SPI机制。
- 插件模块,负责实现具体的业务逻辑,Dubbo SPI接口与实现。
Dubbo中的URL统一资源模型
URL也就是Uniform Resource Locator,中文叫统一资源定位符。Dubbo中无论是服务消费方,或者服务提供方,或者注册中心。都是通过URL进行定位资源的。
那Dubbo中的统一URL资源模型是怎么样的?
1 | protocol://username:password@host:port/path?key=value&key=value |
1 | public URL(String protocol, |