MySQL-主从复制和分库分表
数据库主备搭建
主从架构
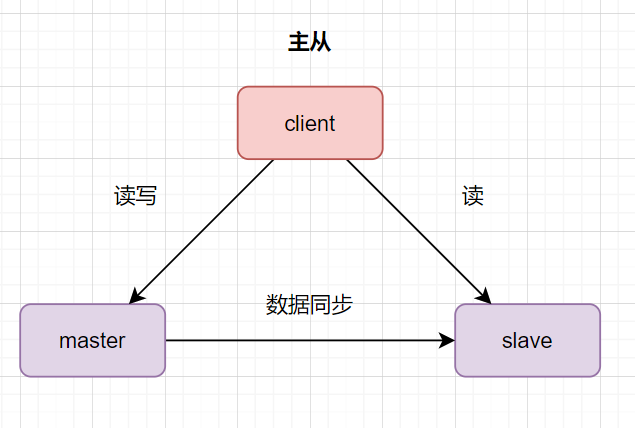
- 主库对外提供读写的操作
- 从库对外提供读的操作
主从架构的优势
- 读写分离,减少主库压力,提升服务性能
- 备份数据
- 高可用,实时灾备
主从架构需要考虑的问题
- 主从一致性
- 主从延迟
主主、主从、主备
- 主主
两台都是主数据库,同时对外提供读写操作。
客户端访问任意一台。
数据存在双向同步。 - 主从
一台是主数据库,对外提供读写操作。
一台是从数据库,对外提供读操作。
数据从主库同步到从库。 - 主备
一台是主数据库,对外提供读写操作。
一台是备库,只作为备份作用,不对外提供读写,主机挂了就取而代之。
数据从主库同步到备库。
主从同步原理
- 主数据库有个
bin log二进制文件,纪录了所有增删改SQL语句。(binlog线程) - 从数据库把主数据库的bin log文件的SQL 语句复制到自己的
中继日志 relay log(io线程) - 从数据库的relay log重做日志文件,再执行一次这些sql语句。(Sql执行线程)
详细的主从同步过程如下: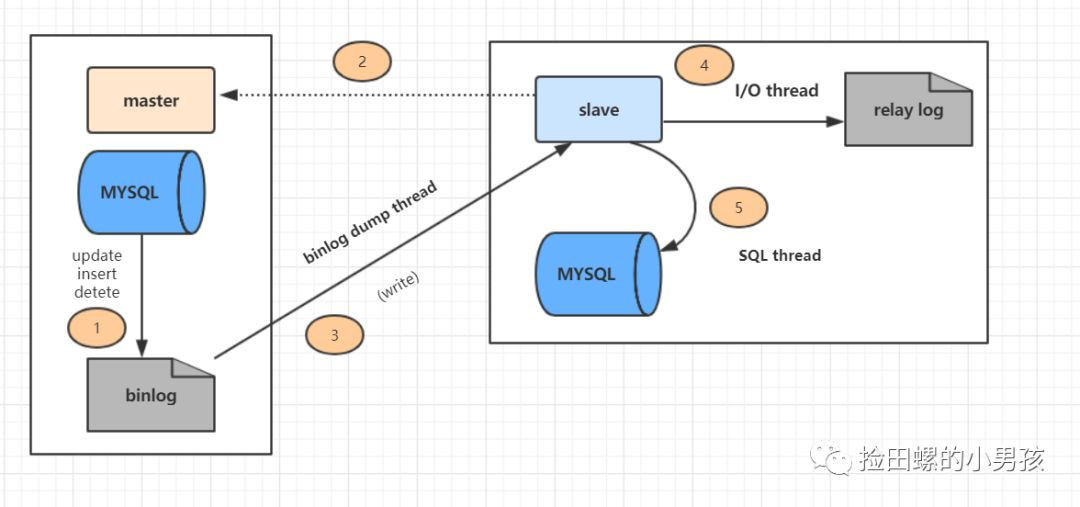
- 主库写 binlog:主库的更新SQL(update、insert、delete)被写到binlog;
- 主库发送 binlog:从库发起连接,连接到主库,此时主库创建一个binlog dump thread,把bin log的内容发送到从库;
- 从库写 relay log:从库启动之后,创建一个I/O线程-io_thread,读取主库传过来的bin log内容并写入到relay log;
- 从库回放:从库还会创建一个SQL线程-sql_thread,从relay log里面读取内容,从ExecMasterLog_Pos位置开始执行读取到的更新事件,将更新内容写入到slave的db。
主从一致性
主从延迟
与主从数据同步相关的时间点有三个:
- 主库执行完一个事务,写入binlog,我们把这个时刻记为T1;
- 主库同步数据给从库,从库接收完这个binlog的时刻,记录为T2;
- 从库执行完这个事务,这个时刻记录为T3。
主从延迟,指一个事务,在从库执行完的时间和在主库执行完的时间差值,即T3-T1。
我们分析一下主从复制的过程。
- MySQL的主从复制都是单线程的操作,主库对所有DDL和DML产生binlog,binlog是顺序写,所以效率很高。
- 从库的IO线程会到主库取binlog日志,放入relay log,效率会比较高。
- 从库的SQL线程将主库的DDL和DML操作都在Slave回放,DML和DDL的IO操作是随机的,不是顺序的,因此成本会很高。
- 还可能是从库上的其他查询产生lock争用,由于从库的SQL执行是单线程的,所以一个DDL卡住了,需要执行10分钟,那么所有之后的DDL会等待这个DDL执行完才会继续执行,这就导致了延时。
总结一下主从延时的主要原因在于从库realy log回放这一步,当主库的TPS并发较高,产生的DDL数量超过从库一个SQL线程所能承受的范围,那么延时就产生了;当然还有可能是与从库的大型query语句产生了锁等待。
导致主从延迟的情况
- 从库机器比主库机器性能差
- 从库的查询压力大,消耗大量CPU,影响同步速度
- 大事务,大表的DDL语句
- 网络延迟
- 从数据库太多
- 低版本的MySQL只支持单线程复制,如果主库并发高,来不及送到从库会导致延迟。
MySQL从5.6开始支持多线程复制。
主从同步延迟如何处理
最容易想到的办法,缩短主从同步时间:
- 提升从库机器配置,可以和主库一样,甚至更好;
- 避免大事务;
- 搞多个从库,即一主多从,分担从库查询压力;
- 优化网络带宽;
- 选择高版本MySQL,支持主库binlog多线程复制。
也可以从业务场景考虑:
- 使用缓存。我们在同步写数据库的同时,也把数据写到缓存,查询数据时,会先查询缓存,不过这种情况会带来 MySQL 和 Redis 数据一致性问题。
- 查询主库。直接查询主库,这种情况会给主库太大压力,核心场景可以使用,比如订单支付。
还可以在MySqL架构上来考虑。
主库对数据安全性的要求较高,设置配置如下:
1 | sync_binlog = 1 |
而从库不需要这么高的数据安全,完全可以将sync_binlog设置为0,或者关闭binlog;innodb_flush_log也可以设置为0,来提高sql的执行效率。
架构方案:使用多台 slave 来分摊读请求,再从这些 slave 中取一台专用的服务器,只作为备份用,不进行其他任何操作,比如设置 sync_binlog 为0,或者关闭 binglog 等,提升从库查询性能。