Java基础 - Q&A
Java基础
面向对象特性
封装、继承、多态
JDK、JRE、JVM
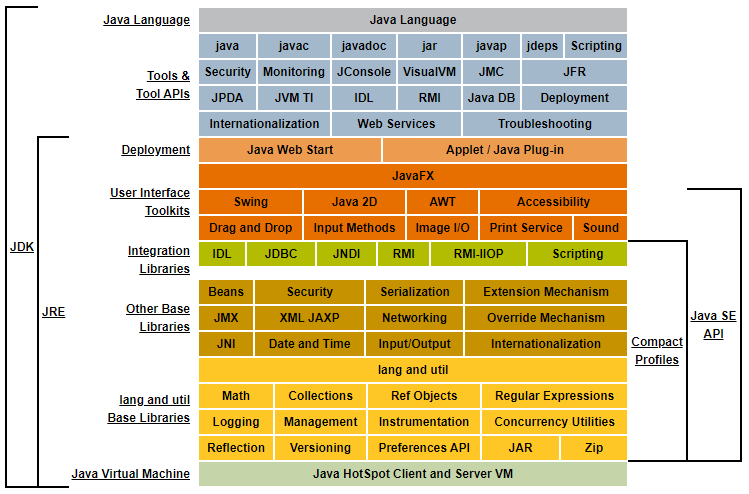
Http请求、Tomcat线程、Java线程
基本数据类型
大小
| 数据类型 | 名称 | 大小(B) 注:1B = 8b | 包装器 |
|---|---|---|---|
| byte | 字节型 | 1 | Byte |
| short | 字符型 | 2 | Short |
| int | 短整型 | 4 | Integer |
| long | 整形 | 8 | Long |
| float | 单精度浮点型 | 4 | Float |
| double | 双精度浮点型 | 8 | Double |
| char | 字符型 | 2 | Character |
| boolean | 布尔 | 不同情况下不同 | Boolean |
Q:为什么char类型是2个字节?
重载(Overload)和重写(Override)的区别?
方法的重载和重写都是实现多态的方式,区别在于重载实现的事编译时的多态性,重写实现的是运行时的多态性。
重载发生在一个类中,同名方法的参数列表(参数类型、参数个数、参数顺序)不同,与返回值类型无关。
重写发生在子类与父类之间,要求方法名、参数列表、返回类型必须相同,访问修饰符的限制要大于被重写方法,不能抛出比被重写方法更宽泛的异常。
String 和 StringBuffer、StringBuilder 的区别?
java.lang.String/StringBuffer/StringBuilder,三者的共同之处都是final类,不允许被继承。
- String
1
2
3
4
5
6public final class String
implements java.io.Serializable, Comparable<String>, CharSequence,
Constable, ConstantDesc {
private final byte[] value;
} - StringBuilder
1
2
3
4
5public final class StringBuilder
extends AbstractStringBuilder
implements java.io.Serializable, Comparable<StringBuilder>, CharSequence
{
} - StringBufferStringBuffer中的许多方法是用
1
2
3
4
5
6
7
8
9
10public final class StringBuffer
extends AbstractStringBuilder
implements Serializable, Comparable<StringBuffer>, CharSequence
{
/**
* A cache of the last value returned by toString. Cleared
* whenever the StringBuffer is modified.
*/
private transient String toStringCache;
}synchronized关键字修饰的。 - AbstractStringBuilder
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16abstract class AbstractStringBuilder implements Appendable, CharSequence {
/**
* The value is used for character storage.
*/
byte[] value;
/**
* The id of the encoding used to encode the bytes in {@code value}.
*/
byte coder;
/**
* The count is the number of characters used.
*/
int count;
}
String
String 为什么是不可变的?
不可变的对象:一个对象在它创建完成之后,不能改变对象内的成员变量,包括基本数据类型的值不能改变,引用类型的变量不能指向其他的对象,引用类型指向的对象的状态也不能改变。
String 用 value[] 来保存字符串。
1 | private final char value[]; |
value[]是final修饰的,不能再指向其他数组对象,但是可以通过反射,反射出String对象的value属性,进而通过获得的value引用改变数组的结构。
String是线程安全的吗?
是。
String是不可变的,多线程操作同一个String变量时,修改String的值只会改变当前String变量的引用,各线程之间该String的引用会不同,但value值不会造成数据污染、覆盖。
string = “” 和 new String的区别
String str1 = “abc”
1
2String str1 = "abc";
System.out.println(str1 == "abc");栈中开辟一块空间存放引用str1;
String池中开辟一块空间,存放String常量”abc”;
引用str1指向池中String常量”abc”;
str1所指代的地址即常量”abc”所在地址,输出为true;String str2 = new String(“abc”);
1
2String str2 = new String("abc");
System.out.println(str2 == "abc");栈中开辟一块空间存放引用str2;
堆中开辟一块空间存放一个新建的String对象”abc”;
引用str2指向堆中的新建的String对象”abc”;
str2所指代的对象地址为堆中地址,而常量”abc”地址在池中,输出为false;String s = new String(“xyz”); 产生几个对象?
一个或两个。如果常量池中原来没有 ”xyz”, 就是两个。如果原来的常量池中存在“xyz”时,就是一个。final String str1 = “a”
1
2
3
4
5
6
7
8
9
10
11
12
13
14// (3)
String str1 = "a";
String str2 = "b";
String str3 = str1 + "b";
//str1 和 str2 是字符串常量,所以在编译期就确定了。
//str3 中有个 str1 是引用,所以不会在编译期确定。
//又因为String是 final 类型的,所以在 str1 + "b" 的时候实际上是创建了一个新的对象,在把新对象的引用传给str3。
//(4)
final String str1 = "a";
String str2 = "b";
String str3 = str1 + "b";
//这里和(3)的不同就是给 str1 加上了一个final,这样str1就变成了一个常量。
//这样 str3 就可以在编译期中就确定了intern()
intern()方法:当调用 intern 方法时,如果常量池已经包含一个等于此 String 对象的字符串(该对象由 equals(Object) 方法确定),则返回常量池中的字符串。否则,将此 String 对象添加到池中,并且返回此 String 对象的引用。1
2
3
4
5
6
7
8String str1 = "ab";
String str2 = new String("ab");
System.out.println(str1== str2);//false
System.out.println(str2.intern() == str1);//true
System.out.println(str1== str2);//false
str2 = str2.intern();
System.out.println(str1== str2);//truestr1 指向的是常量池对象 “ab”;
str2 指向的是堆中的对象 “ab”;
调用了 str2 = str2.intern() 后,str2.intern()判断常量池中是否有 “ab”对象,如果有就返回,没有就创建并返回,此时就返回的 str1 所指向的那个对象 “ab” 。
final、finalize、finally
- final是一个修饰符,可以修饰变量、方法和类
- Java技术允许使用
finalize方法在垃圾收集器将对象从内存中清楚出去之间做必要的清理工作。这个方法是由垃圾收集器在确定这个对象没有被引用时对这个对象调用的,但是什么时候调用没有保证。 - finally是一个关键字,与try、catch一起用于异常的处理。finally块一定会被执行,无论在try块中是否发生异常。
接口与抽象类的区别?
- 一个子类只能继承一个抽象类,但能实现多个接口
- 抽象类可以有构造方法,接口没有构造方法
- 抽象类可以有普通成员变量,接口没有普通成员变量
- 抽象类和接口都可以有静态成员变量。抽象类中静态成员变量访问类型任意,接口只能
public stativ final - 抽象类可以没有抽象方法,抽象类可以有偶同方法;接口在JDK8之前都是抽象方法,在JDK8可以有default方法,在JDK9允许有私有private普通方法
- 抽象类可以有静态方法;接口在JDK8之前不能有静态方法,在JDK8中可以有静态方法,且只能被接口类直接调用(不能被实现类对象调用)
- 抽象类中的方法可以是public、protected;接口方法在JDK8之前只有
publi abstrct,在JDK8可以有default方法,在JDK9允许有私有private普通方法
自动装箱与拆箱
基本数据类型和其包装类型的自动转换。
自动装箱都是通过包装类的valueOf()方法来实现的。
自动拆箱都是通过包装类对象的xxxValue()来实现的。
1 | // 装箱 |
自动拆装箱与缓存
Integer的缓存机制:
- 适用于整数值区间 -128到+127
- 只适用于自动装箱
- 使用构造函数创建对象不适用
当需要进行自动装箱时,如果数字在-128到+127之间,会直接使用缓存中的对象,而不是重新创建一个对象。
== 与 equals()?
- ==
基本数据类型==判断值是否相等;
引用数据类型==判断变量指向的引用地址是否相等。 - equals()方法
基本数据类型没有equals()方法;
Object类中equals方法默认用==比较两个对象的引用地址。
引用数据类型如果没有重写eqals()则是比较两个对象的引用地址。
String类重写了equals方法,比较的是字符串的值。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32public class Object {
public boolean equals(Object obj) {
return (this == obj);
}
}
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence,
Constable, ConstantDesc {
public boolean equals(Object anObject) {
if (this == anObject) {
return true;
}
if (anObject instanceof String) {
String anotherString = (String)anObject;
int n = value.length;
if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0;
while (n-- != 0) {
if (v1[i] != v2[i])
return false;
i++;
}
return true;
}
}
return false;
}
}
Object类的常见方法?
- toString()
获取对象信息方法。将对象的信息变为字符串返回,默认输出对象地址。 - equals(Object obj)
对象相等判断方法。用于比较对象是否相等,而且此方法必须被重写。基本数据类型没有equals()方法。 - hashCode()
对象签名。用来返回该对象的物理地址(哈希码值),常会和equals()方法同时重写,确保两个相等的对象拥有相等的hashcode。 - getClass()
返回此Object的运行时类。常用于反射中。 - wait()
- notify()
- notifyAll()
Java基础 - 序列化和反序列化
认识序列化与反序列化
Java序列化是指把Java对象转换为字节序列的过程;
而Java反序列化是指把字节序列恢复为Java对象的过程。为什么要实现对象的序列化和反序列化
- 我们创建的Java对象被存储在内存的JVM堆中,当程序运行结束后,这些对象会被JVM回收。但在现实的应用中,可能会要求在程序运行结束之后还能读取这些对象,并在以后检索数据,这时就需要用到序列化。
- 当Java对象通过网络进行传输的时候,因为数据只能够以二进制的形式在网络中进行传输,因此当把对象通过网络发送出去之前需要先序列化成二进制数据,当接收端读到二进制数据之后反序列化成Java对象。
序列化与反序列化的实现
被序列化的对象需要实现java.io.Serializable接口,该接口只是一个标记接口,不用实现任何方法。实现了Serializable接口的类可以被
ObjectOutputStream转换为字节流,同时也可以通过ObjectInputStream再将其解析为对象。
例如,我们可以将序列化对象写入文件后,再次从文件中读取它并反序列化成对象,也就是说,可以使用表示对象及其数据的类型信息和字节在内存中重新创建对象。Serializable接口的作用?serialVersionUID 的作用?
Serializable接口是一个对象序列化的接口,一个类只有实现了Serializable接口,它的对象才能被序列化。在序列化的时候系统将serialVersionUID写入到序列化的文件中去,当反序列化的时候系统会先去检测文件中的serialVersionUID是否跟当前的文件的serialVersionUID是否一致,如果一直反序列化不成功,就说明当前类跟序列化后的类发生了变化,比如是成员变量的数量或者是类型发生了变化,那么在反序列化时就会发生crash,并且会报出错误。
如果没有显示的定义serialVersionUID变量的时候,JAVA序列化机制会根据Class自动生成一个serialVersionUID作序列化版本比较用,这种情况下,如果Class文件(类名,方法明等)没有发生变化(增加空格,换行,增加注释等等),就算再编译多次,serialVersionUID也不会变化的。
SpringBoot中的序列化和反序列化
在项目开发中,我们的类并没有实现Serializable接口,实际上这是Spring框架帮我们做了一些事情,Spring并不是直接把Java对象进行网络传输,而是先把Java对象转换成json格式的字符串,然后再进行传输的,而String类实现了Serializable接口并且显示指定了serialVersionUID 。
Java基础 - 泛型
如何理解Java中的泛型是伪泛型
Java泛型这个特性是JDK5才开始加入的,因此为了兼容之前的版本,Java泛型的实现采取了伪泛型的策略,即Java在语法上支持泛型,但是在编译阶段会进行所谓的泛型擦除,将所有的范型表示(尖括号中的内容)都替换为具体的类型(其对应的原生态类型),就像完全没有泛型一样。
Java基础 - 注解
Java基础 - 异常
Java基础 - 反射
什么是反射
Java反射机制是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意一个方法和属性。
这种动态获取信息以及动态调用对象的方法的功能成为Java语言的反射机制。
反射的使用
在Java中,Class类与java.lang.reflect类库一起对反射技术进行了全力的支持。
在反射包中,我们常用的类主要有Constructor类表示的是Class 对象所表示的类的构造方法,利用它可以在运行时动态创建对象、Field表示Class对象所表示的类的成员变量,通过它可以在运行时动态修改成员变量的属性值(包含private)、Method表示Class对象所表示的类的成员方法,通过它可以动态调用对象的方法(包含private)
Java基础 - SPI机制
什么是SPI机制
SPI(Service Provider Interface),是JDK内置的一种 服务提供发现机制,可以用来启用框架扩展和替换组件,主要是被框架的开发人员使用,比如java.sql.Driver接口,其他不同厂商可以针对同一接口做出不同的实现,MySQL和PostgreSQL都有不同的实现提供给用户,而Java的SPI机制可以为某个接口寻找服务实现。
Java中SPI机制主要思想是将装配的控制权移到程序之外,在模块化设计中这个机制尤其重要,其核心思想就是 解耦。
SPI整体机制图如下: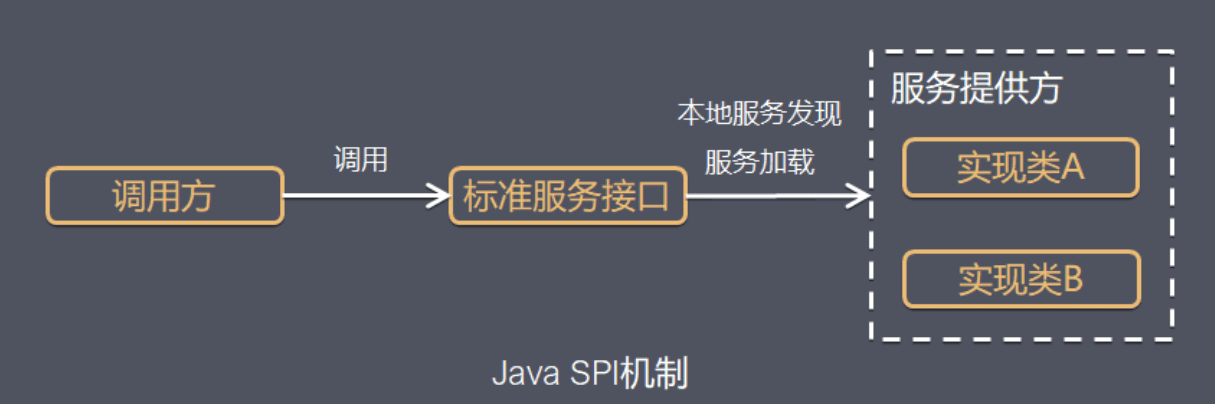
当服务的提供者提供了一种接口的实现之后,需要在classpath下的META-INF/services/目录里创建一个以服务接口命名的文件,这个文件里的内容就是这个接口的具体的实现类。当其他的程序需要这个服务的时候,就可以通过查找这个jar包(一般都是以jar包做依赖)的META-INF/services/中的配置文件,配置文件中有接口的具体实现类名,可以根据这个类名进行加载实例化,就可以使用该服务了。JDK中查找服务的实现的工具类是:java.util.ServiceLoader。
SPI机制的应用
JVM
描述一下 JVM 加载 Class 文件的原理机制?
什么是tomcat类加载机制?
类加载器双亲委派模型机制?可以打破双亲委派吗?怎么打破?
垃圾回收常见问题。
什么是GC? 为什么要有 GC?
简述一下Java 垃圾回收机制?
如何判断一个对象是否存活?
垃圾回收的优点和原理,并考虑 2 种回收机制?
Java 中垃圾收集的方法有哪些?
讲讲你理解的性能评价及测试指标?
常用的性能优化方式有哪些?
集合
Arraylist 与 LinkedList 异同。
ArrayList 与 Vector 区别。
HashMap的底层实现。
HashMap 和 Hashtable 的区别。
HashMap 的长度为什么是2的幂次方。
HashMap 多线程操作导致死循环问题。
HashSet 和 HashMap 区别。
ConcurrentHashMap 和 Hashtable 的区别。
- HashTable是线程安全的,原理和HashMap基本一样,差别在:
- HashTable不允许key和value为null
- get/put所有相关操作都是synchronized的,这相当于给整个哈希表加了一把大锁,性能较差
- ConcurrentHashMap是线程安全的,但是它是分段锁,容器中有多把锁,每一把锁锁一段数据,这样在多线程访问时不同段的数据时,就不会存在锁竞争了,这样便可以有效地提高并发效率。
ConcurrentHashMap线程安全的具体实现方式/底层具体实现。
JUC 多线程与并发
Thread、Runnable、Callable、Future、FutureTask,谈谈它们的关系?
AQS 原理。
AQS 对资源的共享方式。
AQS底层使用了模板方法模式。
transient关键字
synchronized关键字。
说说自己是怎么使用 synchronized 关键字,在项目中用到了吗?
面试题:多线程循环打印ABC
1 | /** |
1 | /** |
1 | package com.feng.thread; |
讲一下 synchronized 关键字的底层原理。
说说 JDK1.6 之后的synchronized 关键字底层做了哪些优化,可以详细介绍一下这些优化吗?
谈谈 synchronized和ReenTrantLock 的区别。
说说 synchronized 关键字和 volatile 关键字的区别。
为什么要用线程池?
实现Runnable接口和Callable接口的区别。
执行execute()方法和submit()方法的区别是什么呢?
如何创建线程池。
介绍一下Atomic 原子类。
JUC 包中的原子类是哪4类?
- 基本类型: AtomicInteger, AtomicLong, AtomicBoolean ;
- 数组类型: AtomicIntegerArray, AtomicLongArray, AtomicReferenceArray ;
- 引用类型: AtomicReference, AtomicStampedRerence, AtomicMarkableReference ;
- 对象的属性修改类型: AtomicIntegerFieldUpdater, AtomicLongFieldUpdater, AtomicReferenceFieldUpdater 。
讲讲 AtomicInteger 的使用。
能不能给我简单介绍一下 AtomicInteger 类的原理?
设计模式
单例模式
- 懒汉式:在第一次调用的时候进行实例化。
- 饿汉式:在类初始化时,已经自行实例化。
饿汉式 - 直接静态初始化
- 优点:简单,含有 final 关键字
- 缺点:程序运行直接加载,耗费资源
1 | public class SingletonObject1 { |
懒汉式 - synchronized实现
- 优点:懒加载实现,即初次获取值时才会初始化
- 缺点:synchronized 实现,初始化后每次读操作也会加锁,耗费资源
1 | public class SingletonObject3 { |
懒汉式 - 双重检查
- 优点:懒加载 + 双重检查,确保初始化一次,同时优化性能
- 缺点:实现较复杂,同时 volatile 也有性能损耗
1 | public class SingletonObject4 { |
静态内部类
加载一个类时,其内部类不会同时被加载。
一个类被加载,当且仅当其某个静态成员(静态域、构造器、静态方法等)被调用时发生。
由于在调用 SingletonObject5.getInstance() 的时候,才会对单例进行初始化,而且通过反射,是不能从外部类获取内部类的属性的;由于静态内部类的特性,只有在其被第一次引用的时候才会被加载,所以可以保证其线程安全性。
- 优点:使用内部类机制实现懒加载,最佳实践之一
1 | public class SingletonObject5 { |
枚举方式
单元素的枚举类型已经成为实现Singleton的最佳方法。
1 | public enum EnumSingleton { |
策略模式 + 模板模式 + 工厂模式
- 使用策略模式结合InitializingBean或ApplicationContextAware简化if-else
- 模板模式抽取公共方法
- 工厂模式:根据不同策略请求类型去拿不同的策略去调用
线程池
- 为什么会有线程池?
- 简单手写一个线程池?
池内工作线程的管理、任务编排执行、线程池超负荷处理方案(拒绝策略)、监控。 - 为什么要把任务先放在任务队列里面,而不是把线程先拉满到最大线程数?
- 线程池如何动态修改核心线程数和最大线程数?
其实之所以会有这样的需求是因为线程数是真的不好配置。
线程数真的很难通过一个公式一劳永逸,线程数的设定是一个迭代的过程,需要压测适时调整。再者,流量的突发性也是无法判断的,举个例子 1 秒内一共有 1000 个请求量,但是如果这 1000 个请求量都是在第一毫秒内瞬时进来的呢?
原生线程池ThreadPoolExecutor已经提供修改配置的方法,也对外暴露出线程池内部执行情况,所以只要我们实时监控情况,调用对应的set方法,即可动态修改线程池对应配置。 - 如果你是 JDK 设计者,如何设计?
- 如果要让你设计一个线程池,你要怎么设计?
- 你是如何理解核心线程的?
- 你是怎么理解 KeepAliveTime 的?
- 那 workQueue 有什么用?
- 你是如何理解拒绝策略的?
- 你说你看过源码,那你肯定知道线程池里的 ctl 是干嘛的咯?
runState、workerCount - 你知道线程池有几种状态吗?
- 你知道线程池的状态是如何变迁的吗?
- 如何修改原生线程池,使得可以先拉满线程数再入任务队列排队?
参考Tomcat的定制化线程池实现。代码里出现的TaskQueue,这个就是Tomcat线程池的定制关键点了。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33public void execute(Runnable command, long timeout, TimeUnit unit) {
// 统计提交的任务数+1
submittedCount.incrementAndGet();
try {
// 调用JDK原生线程池ThreadPoolExecutor的execute方法提交任务
executeInternal(command);
} catch (RejectedExecutionException rx) { // 拒绝异常
// TaskQueue
if (getQueue() instanceof TaskQueue) {
// If the Executor is close to maximum pool size, concurrent
// calls to execute() may result (due to Tomcat's use of
// TaskQueue) in some tasks being rejected rather than queued.
// If this happens, add them to the queue.
final TaskQueue queue = (TaskQueue) getQueue();
try {
// 再次尝试把任务塞进任务队列里
if (!queue.force(command, timeout, unit)) {
// 如果塞不进去,把之前统计的任务数-1
submittedCount.decrementAndGet();
throw new RejectedExecutionException(sm.getString("threadPoolExecutor.queueFull"));
}
} catch (InterruptedException x) {
// 被打断了,任务数-1
submittedCount.decrementAndGet();
throw new RejectedExecutionException(x);
}
} else {
// 如果不是定制的任务队列,任务数-1
submittedCount.decrementAndGet();
throw rx;
}
}
}
Tomcat自定义队列TaskQueue重写了LinkedBlockingQueue的offer方法,这是关键所在!1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28public class TaskQueue extends LinkedBlockingQueue<Runnable> {
// 线程池调用任务队列的方法时,当前线程数肯定已经大于核心线程数了
public boolean offer(Runnable o) {
// 没有找到Tomcat扩展线程池的话,直接调用父类的offer方法
if (parent==null) {
return super.offer(o);
}
// 如果线程数已经到了最大值,不能创建新线程了,只能把任务添加到任务队列
if (parent.getPoolSizeNoLock() == parent.getMaximumPoolSize()) {
return super.offer(o);
}
// 执行到这里,表明当前线程数大于核心线程数 && 小于最大线程数
// 表明是可以创建新线程的,分两种情况
// 1. 如果已提交的任务数小于当前线程数,表示还有空闲线程,无需创建新线程
if (parent.getSubmittedCount() <= parent.getPoolSizeNoLock()) {
return super.offer(o);
}
// 2. 如果已提交的任务数大于当前线程数,返回false去创建新线程
if (parent.getPoolSizeNoLock() < parent.getMaximumPoolSize()) {
return false;
}
// 默认情况
return super.offer(o);
}
} - Tomcat中的定制化线程池实现,如果线程池中的线程在执行任务的时候,抛异常了,会怎么样?
- 原生线程池的核心线程一定伴随着任务慢慢创建的吗?
并不是,线程池提供了两个方法:- prestartCoreThread:启动一个核心线程
- prestartAllCoreThreads :启动所有核心线程
不要小看这个预创建方法,预热很重要,不然刚重启的一些服务有时是顶不住瞬时请求的,就立马崩了,所以有预热线程、缓存等等操作。
- 线程池的核心线程在空闲的时候一定不会被回收吗?
有个allowCoreThreadTimeOut参数,把它设置为 true ,则所有线程都会超时,不会有核心数那条线的存在。
具体是会调用interruptIdleWorkers这个方法。