分布式缓存
缓存分类
客户端缓存/浏览器缓存
对于B/S架构的互联网应用来说客户端缓存主要分为页面缓存和浏览器缓存两种,对于APP而言主要是自身所使用的缓存。
客户端Client/Server是建立在局域网的基础上的。浏览器Browser/Server是建立在广域网的基础上的。
网络中缓存
- CDN缓存
- 代理服务器缓存
服务端缓存
- 本地缓存
- 分布式缓存,Redis、Memcached、MongoDB等NoSql
- 数据库缓存
CDN缓存
CDN是什么
Content Delivery Network,内容分发网络,是建立并覆盖在承载网之上,由分布在不同区域的边缘节点服务器群组成的分布式网络。
CDN是将源站内容(image、html、js、css等)分发至全国所有的节点,从而缩短用户查看对象的延迟,提高用户访问网站的响应速度与网站的可用性的技术。它能够有效解决网络带宽小、用户访问量大、网点分布不均等问题。
代理服务器缓存
代理服务器
Proxy Server,其功能就是代理网络用户去取得网络信息。
形象的说:它是网络信息的中转站。在一般情况下,我们使用网络浏览器直接去连接其他Internet站点取得网络信息时,须送出Request信号来得到回答,然后对方再把信息以bit方式传送回来。代理服务器是介于浏览器和Web服务器之间的一台服务器,有了它之后,浏览器不是直接到Web服务器去取回网页而是向代理服务器发出请求,Request信号会先送到代理服务器,由代理服务器来取回浏览器所需要的信息并传送给你的浏览器。而且,大部分代理服务器都具有缓冲的功能,就好象一个大的Cache,它有很大的存储空间,它不断将新取得数据储存到它本机的存储器上,如果浏览器所请求的数据在它本机的存储器上已经存在而且是最新的,那么它就不重新从Web服务器取数据,而直接将存储器上的数据传送给用户的浏览器,这样就能显著提高浏览速度和效率。
代理功能
- 突破自身IP访问限制,访问国外站点。教育网、169网等网络用户可以通过代理访问国外网站。
- 访问一些单位或团体内部资源。如某大学FTP(前提是该代理地址在该资源 的允许访问范围之内),使用教育网内地址段免费代理服务器,就可以用于对教育网开放的各类FTP下载上传,以及各类资料查询共享等服务。
- 突破中国电信的IP封锁。中国电信用户有很多网站是被限制访问的,这种限制是人为的,不同Serve对地址的封锁是不同的。所以不能访问时可以换一个国外的代理服务器试试。
- 提高访问速度。通常代理服务器都设置一个较大的硬盘缓冲区,当有外界的信息通过时,同时也将其保存到缓冲区中,当其他用户再访问相同的信息时, 则直接由缓冲区中取出信息,传给用户,以提高访问速度。
- 隐藏真实IP。上网者也可以通过这种方法隐藏自己的IP,免受攻击。
Nginx缓存
- 定义缓存存储目录并指定共享内存空间
- 在location里指定共享内存空间
本地缓存
即内存,本地缓存是一级缓存,位于服务本机的内存中,读写速度快,缺点是不能持久化,一旦项目关闭,数据就会丢失,而且不能满足分布式系统的应用场景(比如数据不一致的问题)。
存在的问题:
- 本读缓存数据直接保存在JVM中,需要考虑缓存数据的大小、JVM的垃圾回收性能消耗
- 单服务是集群部署的时候,应该考虑是否需要做集群中本地缓存的数据同步
- 无法进行持久化
- 无法保证多实例数据一致性
EhCache
Guava
Caffeine
Redis缓存
利用缓存数据库,最常见的就是Redis。Redis的访问速度同样很快,可以设置过期时间、设置持久化方法,缺点是会受到网络和并发访问的影响。
Redis的Java客户端
Jedis
Jedis 是直连模式,在多个线程间共享一个 Jedis 实例是线程不安全的,每个线程都去拿自己的 Jedis 实例,当连接数量增多时,物理连接成本就较高了。
底层使用阻塞的I/O,且其方法调用都是同步的,程序流需要等到sockets处理完I/O才能执行,不支持异步。Jedis客户端实例不是线程安全的,所以需要通过连接池来使用Jedis。
Lettuce
相比较Jedis,Lettuce基于优秀Netty NIO框架构建,支持Redis的高级功能,如Sentinel,集群,流水线,自动重新连接和Redis数据模型,线程安全,适用于分布式缓存。
如果需要集群、读写分离、异步等特性支持需要使用Lettuce客户端。
Redission
让使用者对Redis的关注分离,提供很多分布式相关操作服务,例如,分布式锁,分布式集合,可通过Redis支持延迟队列,也是基于Netty框架的事件驱动的通信层。
Spring Data Redis
Spring Data Redis是Spring大家族的一部分,提供了在Srping应用中通过简单的配置访问Redis服务,对Reids底层开发包(Jedis, JRedis, RJC)进行了高度封装,RedisTemplate提供了Redis各种操作、异常处理及序列化,支持发布订阅。
Memcached
缓存淘汰策略
算法
FIFO 先进先出
LRU(Least Recently Used)
最近最少使用。淘汰最长时间没有被使用的,以时间作为参考。
LFU(Least Frequently Used)
最不经常使用。淘汰一段时间内,使用次数最少的,以次数作为参考。
Redis缓存淘汰策略
- volatile-lru:从已设置过期时间的数据集中挑选最近最少使用的数据淘汰。
- volatile-ttl:从已设置过期时间的数据集中挑选将要过期的数据淘汰。
- volatile-random:从已设置过期时间的数据集中任意选择数据淘汰。
- volatile-lfu:从已设置过期时间的数据集挑选使用频率最低的数据淘汰。
- allkeys-lru:从数据集中挑选最近最少使用的数据淘汰。
- allkeys-lfu:从数据集中挑选使用频率最低的数据淘汰。
- allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰。
- no-enviction(驱逐):禁止驱逐数据,这也是默认策略。意思是当内存不足以容纳新入数据时,新写入操作就会报错,请求可以继续进行,线上任务也不能持续进行,采用no-enviction策略可以保证数据不被丢失。
总体上分为4种:
- lru
- lfu
- random
- ttl
缓存、数据库(最终)一致性
主要有两种情况,会导致缓存和DB的一致性问题:
- 并发的场景下,导致读取老的DB数据,更新到缓存中
- 缓存和DB的操作,不在一个事务中,可能只有一个操作成功,而另一个操作失败,导致不一致
- 数据库主从结构,主从同步不及时带来的缓存、数据库数据不一致
延迟双删
数据更新前后双删除缓存策略1
2
3
4
5
6
7
8
9
10
11public void write(String key,Object data){
redis.del(key);
db.update(data);
Thread.sleep(1000);
redis.del(key);
} - 先淘汰缓存
- 写数据库
- 休眠1秒,再次淘汰缓存。高并发情况下确保读请求结束,写请求可以删除读请求造成的缓存脏数据。
延迟双删 - 同步删除,吞吐量降低如何处理
将第二次删除作为异步的,提交一个延迟的执行任务延迟双删 - 解决删除失败的方式
添加重试机制,例如:将删除失败的key,写入消息队列;但对业务耦合有些严重;
一二级缓存一致性
缓存雪崩
什么是缓存雪崩
对于系统 A,假设每天高峰期每秒 5000 个请求,本来缓存在高峰期可以扛住每秒 4000 个请求,但是缓存机器意外发生了全盘宕机。缓存挂了,此时 1 秒 5000 个请求全部落数据库,数据库必然扛不住,它会报一下警,然后就挂了。此时,如果没有采用什么特别的方案来处理这个故障,DBA 很着急,重启数据库,但是数据库立马又被新的流量给打死了。
这就是缓存雪崩。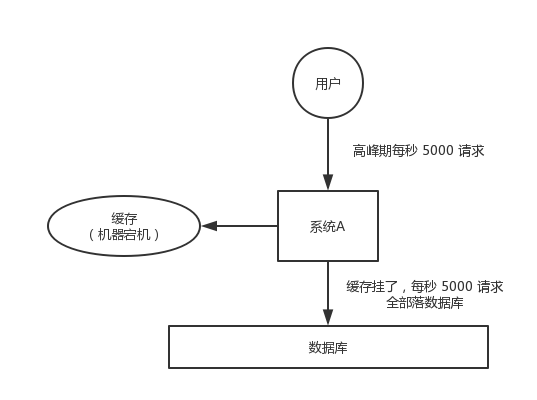
解决方案
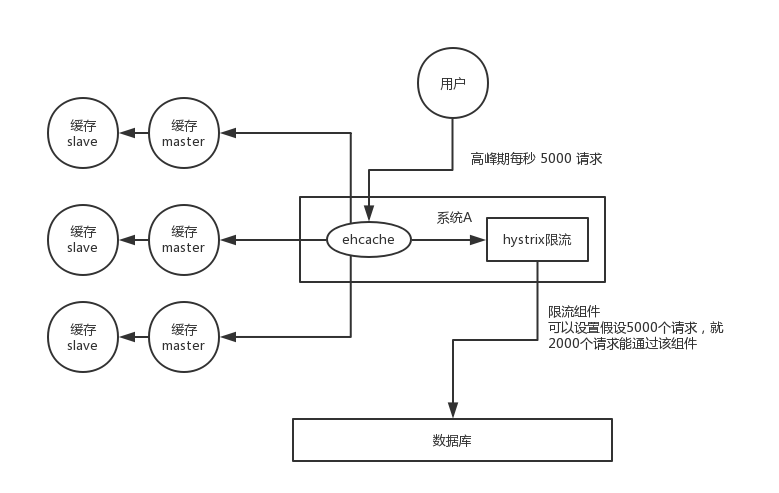
- 事前:redis 高可用,主从+哨兵,redis cluster,避免全盘崩溃。
- 事中:本地 ehcache 缓存 + hystrix 限流&降级,避免 MySQL 被打死。
- 事后:redis 持久化,一旦重启,自动从磁盘上加载数据,快速恢复缓存数据。
缓存穿透
什么是缓存穿透
对于系统A,假设一秒 5000 个请求,结果其中 4000 个请求是黑客发出的恶意攻击。
黑客发出的那 4000 个攻击,缓存中查不到,每次你去数据库里查,也查不到。
举个栗子。数据库 id 是从 1 开始的,结果黑客发过来的请求 id 全部都是负数。这样的话,缓存中不会有,请求每次都“视缓存于无物”,直接查询数据库。这种恶意攻击场景的缓存穿透就会直接把数据库给打死。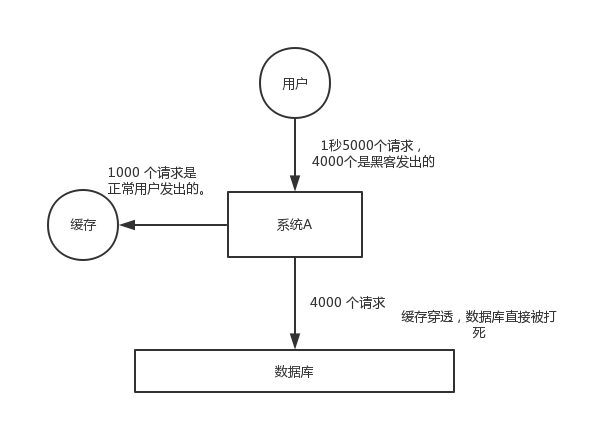
解决方案
缓存空值,并设置过期时间。
每次系统 A 从数据库中只要没查到,就写一个空值到缓存里去,比如 set -999 UNKNOWN。然后设置一个过期时间,这样的话,下次有相同的 key 来访问的时候,在缓存失效之前,都可以直接从缓存中取数据。
缓存击穿
什么是缓存击穿
缓存击穿,就是说某个 key 非常热点,访问非常频繁,处于集中式高并发访问的情况,当这个 key 在失效的瞬间,大量的请求就击穿了缓存,直接请求数据库,就像是在一道屏障上凿开了一个洞。
解决方案
可以将热点数据设置为永远不过期;或者基于 redis or zookeeper 实现互斥锁,等待第一个请求构建完缓存之后,再释放锁,进而其它请求才能通过该 key 访问数据。
热数据
数据并发竞争
redis的并发竞争问题是什么
多客户端同时并发写一个 key,可能本来应该先到的数据后到了,导致数据版本错了;或者是多客户端同时获取一个 key,修改值之后再写回去,只要顺序错了,数据就错了。
如何解决
某个时刻,多个系统实例都去更新某个 key。可以基于 zookeeper 实现分布式锁。每个系统通过 zookeeper 获取分布式锁,确保同一时间,只能有一个系统实例在操作某个 key,别人都不允许读和写。